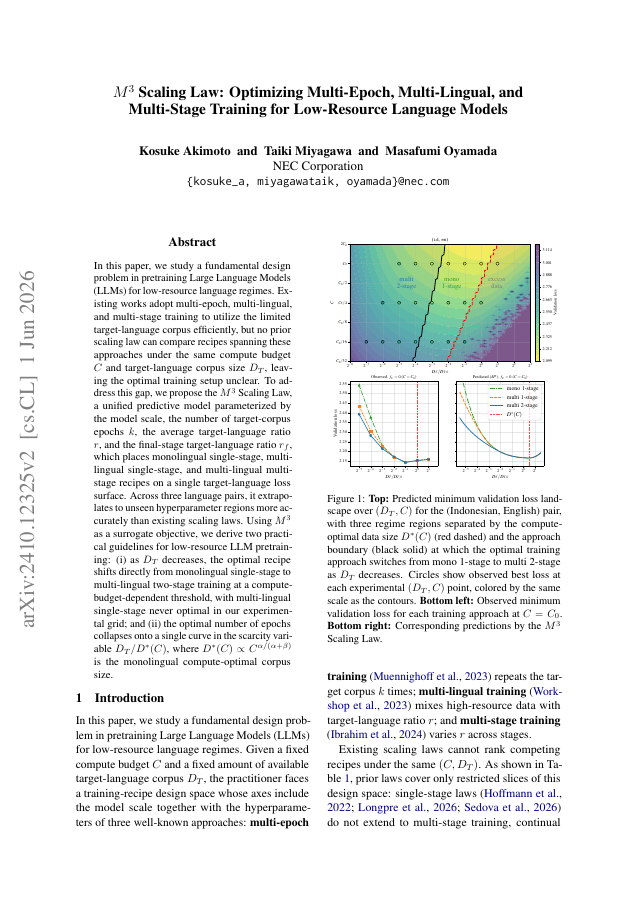
In this paper, we study a fundamental design problem in pretraining Large Language Models (LLMs) for low-resource language regimes. Existing works adopt multi-epoch, multi-lingual, and multi-stage training to utilize the limited target-language corpus efficiently, but no prior scaling law can compare recipes spanning these approaches under the same compute budget $C$ and target-language corpus size $D_T$, leaving the optimal training setup unclear. To address this gap, we propose the $M^3$ Scaling Law, a unified predictive model parameterized by the model scale, the number of target-corpus epochs $k$, the average target-language ratio $r$, and the final-stage target-language ratio $r_f$, which places monolingual single-stage, multi-lingual single-stage, and multi-lingual multi-stage recipes on a single target-language loss surface. Across three language pairs, it extrapolates to unseen hyperparameter regions more accurately than existing scaling laws. Using $M^3$ as a surrogate objective, we derive two practical guidelines for low-resource LLM pretraining: (i) as $D_T$ decreases, the optimal recipe shifts directly from monolingual single-stage to multi-lingual two-stage training at a compute-budget-dependent threshold, with multi-lingual single-stage never optimal in our experimental grid; and (ii) the optimal number of epochs collapses onto a single curve in the scarcity variable $D_T/D^(C)$, where $D^(C) \propto C^{α/(α+β)}$ is the monolingual compute-optimal corpus size.
$M^3$ Scaling Law: Optimizing Multi-Epoch, Multi-Lingual, and Multi-Stage Training for Low-Resource Language Models
In this paper, we study a fundamental design problem in pretraining Large Language Models (LLMs) for low-resource language regimes. Existing works adopt multi-epoch, multi-lingual, and multi-stage training to utilize the limited target-language corpus efficiently, but no prior…
- Preview
- Year
- 2024
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2410.12325CC-BY-4.0
- TL;DR
- Semantic Scholar