Feed
Trending and latest across evals, tools, models, and papers.
Languages with rich static semantics, such as Rust, provide stronger guarantees for AI-generated code, but their strictness makes generation more difficult. Off-the-shelf compilers can provide useful feedback post-generation, but does not guide intermediate generation steps,…

As Large Language Models (LLMs) evolve into autonomous agents, the need for unified evaluation infrastructure becomes critical. However, current evaluation pipelines remain highly fragmented and tightly coupled, hindering reproducibility and causing redundant engineering.

Discrete denoising diffusion models (DDMs) have recently emerged as a compelling alternative to autoregressive (AR) modeling for discrete data, offering parallel generation and iterative global refinement capabilities.

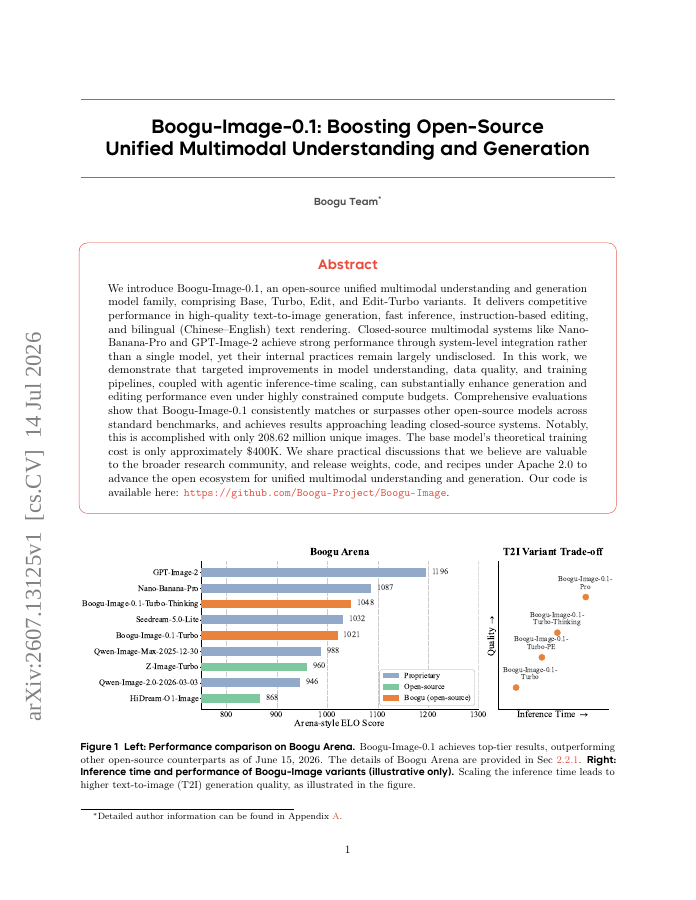
We introduce Boogu-Image-0.1, an open-source unified multimodal understanding and generation model family, comprising Base, Turbo, Edit, and Edit-Turbo variants. It delivers competitive performance in high-quality text-to-image generation, fast inference, instruction-based…
Self-improving autonomous agents are moving from research prototypes to deployed systems. The primary goal is controllable evolution, or adaptation, from experience with minimal or even no human input.

OpenClaw has emerged as a leading agent framework for complex task automation, yet it faces insufficient cross-platform GUI interaction support and a well-built self-evolution mechanism.

Large Language Model (LLM) agents have moved beyond generating responses to executing multi-step tasks by calling tools, observing the results, and iteratively deciding the next action. Most agent systems run on desktops or servers, which support tool use and task automation.

While recent advances in 3D generation have enabled impressive visual synthesis, existing methods often rely on 2D diffusion supervision without explicit mechanisms for geometric consistency, leading to spatial hallucinations such as duplicated structures and misaligned…

Coding agents must integrate external tool returns into ongoing reasoning - a capability that standard left-to-right pretraining on code exposes only in its forward direction.

Multi-scene navigation (clearing an objective in one bounded space and then crossing a portal into the next) is a defining feature of contemporary 3D games, but authoring it is laborious: every portal must have consistent endpoints on both sides, each interior must remain…

When should an intelligent assistant speak up without being asked? Continuous egocentric video offers rich, evolving context that enables a new form of assistance: one that is proactive rather than merely reactive.

Bayesian optimization is increasingly used to guide data-efficient experimentation in chemistry, materials science, and related laboratory settings, but its practical performance depends strongly on how well surrogate-model assumptions match the geometry and noise structure of…

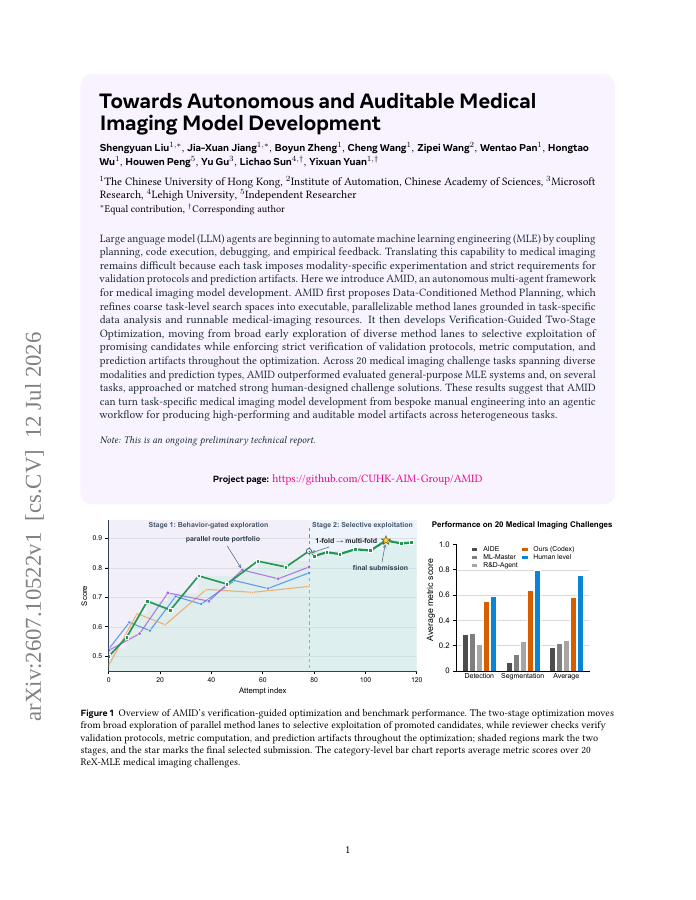
Large language model (LLM) agents are beginning to automate machine learning engineering (MLE) by coupling planning, code execution, debugging, and empirical feedback. Translating this capability to medical imaging remains difficult because each task imposes modality-specific…
Vision language models (VLMs) have achieved strong performance on visual document understanding benchmarks such as DocVQA, ChartQA, and MMLongBench-Doc. However, real-world documents combine multiple factors such as length, layout complexity, modality, and question difficulty,…

We present Soofi S 30B-A3B, a sovereign, open-source Mixture-of-Experts (MoE) hybrid Mamba Transformer foundation model for German and English. Its hybrid design activates only 3B of 30B parameters per token and keeps the inference cache near-constant as context grows, giving it…

Phone segmentation and recognition are inherently related tasks, yet modern approaches typically model them separately. We argue that phonetic structure is already latent in the representations of self-supervised speech models (S3Ms), and one only needs to steer them to solve…

Vision-language-action models (VLAs) inherit semantic capabilities from pretrained VLMs, yet large-scale post-training on robot data and architectural modifications can reshape the backbone so extensively that it becomes difficult to isolate what the VLM contributes to control.

AI agents have become capable of autonomously completing short, well-specified tasks. However, existing terminal benchmarks largely focus on simple problems that finish within minutes and are evaluated only by their final outcome.

Scientific ideas rarely start from a blank page. They inherit mechanisms, repair known limitations, and recombine pieces of earlier work, much like biological genomes. Current benchmarks still say little about whether AI systems can follow this inheritance structure.

Current computational approaches for drug design typically focus on generating molecules conditioned on specific targets or general molecular properties, often neglecting the influence of disease context on target behavior and therapeutic outcomes.

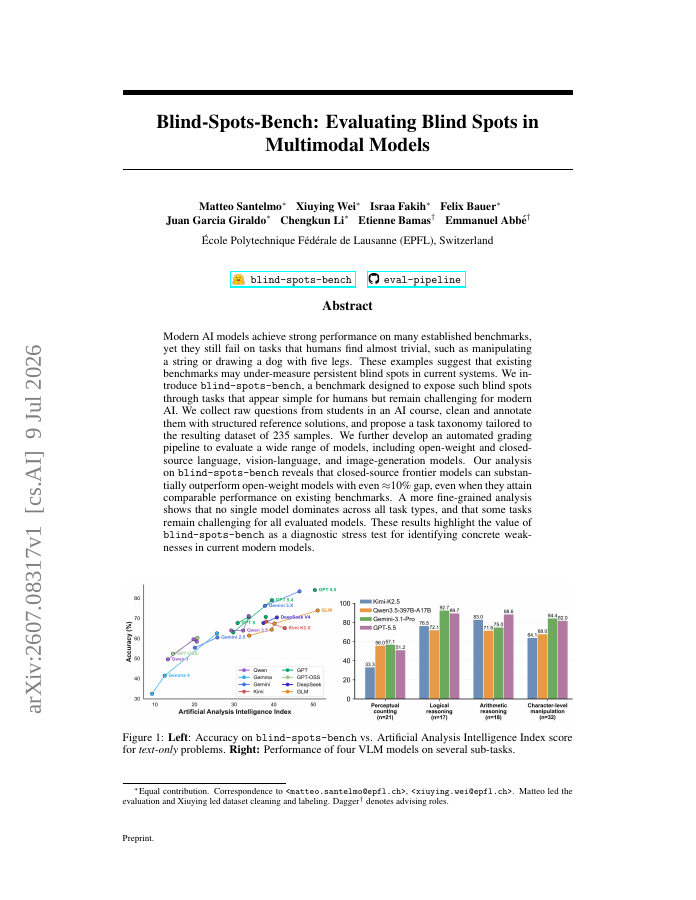
Modern AI models achieve strong performance on many established benchmarks, yet they still fail on tasks that humans find almost trivial, such as manipulating a string or drawing a dog with five legs.
The rapid development of large language models and multimodal large language models has accelerated the emergence of proactive agents capable of operating everyday tools and assisting users in real-world environments.

In long-horizon tasks, decision-relevant state is often scattered across an expanding trajectory, while the action agent must surface it and act. As trajectories grow, task requirements, environment facts, prior attempts, diagnoses, and open subgoals can be buried in the context…

Existing methods for automatic music transcription are often limited to single-instrument recordings or fail on complex, real music mixes. Although previous work utilizes synthetic training data, the resulting models generalize poorly, leading to largely unusable transcription…

Large language models (LLMs) increasingly act as integrated data-science agents, combining abstract reasoning with advanced tool use. Yet the relevant benchmark landscape largely divides into symbolic causal reasoning benchmarks without realistic data analysis or data analysis…

Post-training quantization (PTQ) is a widely adopted technique for compressing large language models (LLMs) without retraining. Existing second-order PTQ methods, including GPTQ, construct quantization objectives exclusively from input activation statistics, effectively assuming…

Self-attention lets each token retrieve information from the full context, but its quadratic cost in sequence length limits training and inference at long context. This paper presents a comparative study of softmax attention and four recent recurrent linear-attention…

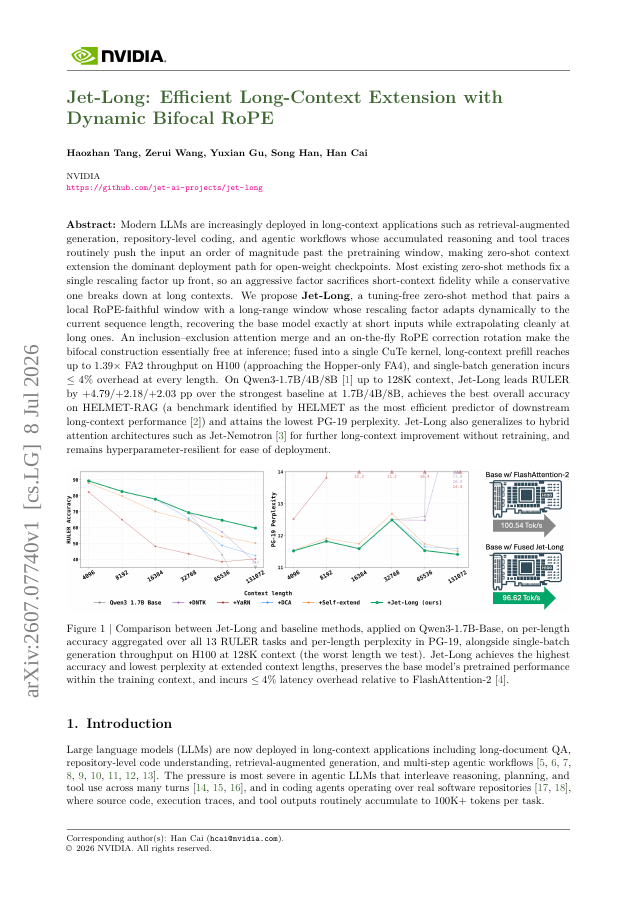
Modern LLMs are increasingly deployed in long-context applications such as retrieval-augmented generation, repository-level coding, and agentic workflows whose accumulated reasoning and tool traces routinely push the input an order of magnitude past the pretraining window,…
Medicine is inherently multimodal, requiring clinicians to synthesize information across diverse data streams. Yet the development of multimodal foundation models is constrained by limited access to large-scale, high-quality clinical data.

Structure-property relationships are foundational to biology, chemistry and materials science, where function, reactivity and physical response emerge from spatial, chemical and periodic organization.

Interactive simulators have become powerful tools for training embodied agents and generating synthetic visual data, but existing photorealistic simulators suffer from limited generality, programmability, and rendering speed.

We present AgentLens, a production-assessed benchmark for interactive code agents. Most code-agent benchmarks reduce a run to a single bit -- did the task pass? -- but the people who actually use these agents experience the entire trajectory: how the agent follows instructions,…

Accurate breast cancer classification from mammography requires effective integration of complementary information from craniocaudal (CC) and mediolateral oblique (MLO) views, which provide a more complete characterization of breast abnormalities.

Mathematical reasoning has become a central task for evaluating and tuning reasoning Large Language Models (LLMs), yet existing benchmarks remain heavily biased toward high-resource languages, with English and Chinese dominating both pre-training corpora and evaluation suites.

Every chemical language model reading SMILES begins with a tokenizer, yet the field has inherited byte-pair encoding (BPE) from natural language with little scrutiny. In natural language, BPE's principal alternative, Unigram-LM, is known to build structurally different…

Pretraining scaling laws reveal that model capability improves predictably with data and compute. But learning from real world environments after deployment remains far less understood.

We introduce PAST-TIDE, our stance detection system addressing both subtasks of the StanceNakba Shared Task at NakbaNLP@LREC-COLING 2026. The main idea is statement tuning.

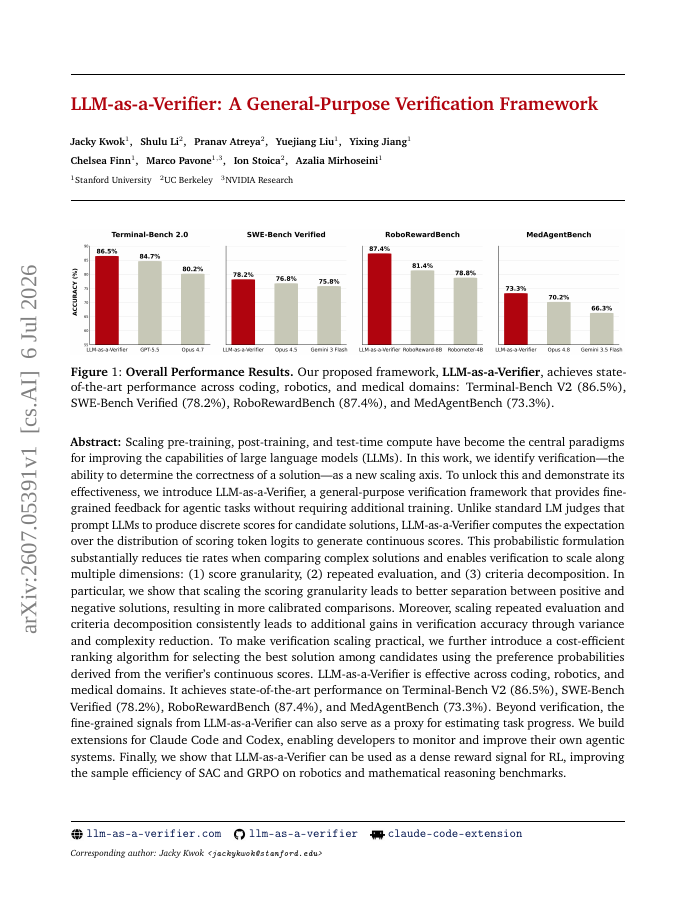
Scaling pre-training, post-training, and test-time compute have become the central paradigms for improving the capabilities of LLMs. In this work, we identify verification, the ability to determine the correctness of a solution, as a new scaling axis.
Visual generators excel at rendering, but they confidently fabricate what they do not know. User requests are unbounded, evolving, and deeply long-tailed: new characters, trending entities, post-cutoff events, and more.

For robots to work reliably in commercial and industrial applications, can recent advances in agentic coding systems combine interpretable robot programming with the open-world adaptability of model-free policies? We focus on "Variational Automation" (VA), a class of…

We introduce the first multiplayer world model for highly dynamic environments governed by complex physical interactions. Whereas single-player world models treat the other agents as part of the environment, ours conditions on the action streams of multiple agents, learning to…

Multi-vector vision-language retrieval preserves fine-grained visual evidence through maximum-similarity late interaction, but dense image-side tokens make storage and scoring expensive.

We present the AI Wizards submission to EXIST 2026 for multimodal sexism identification in memes. The task is composed of three, increasingly harder subtasks. We model them hierarchically as conditional soft-label prediction over empirical annotator distributions.

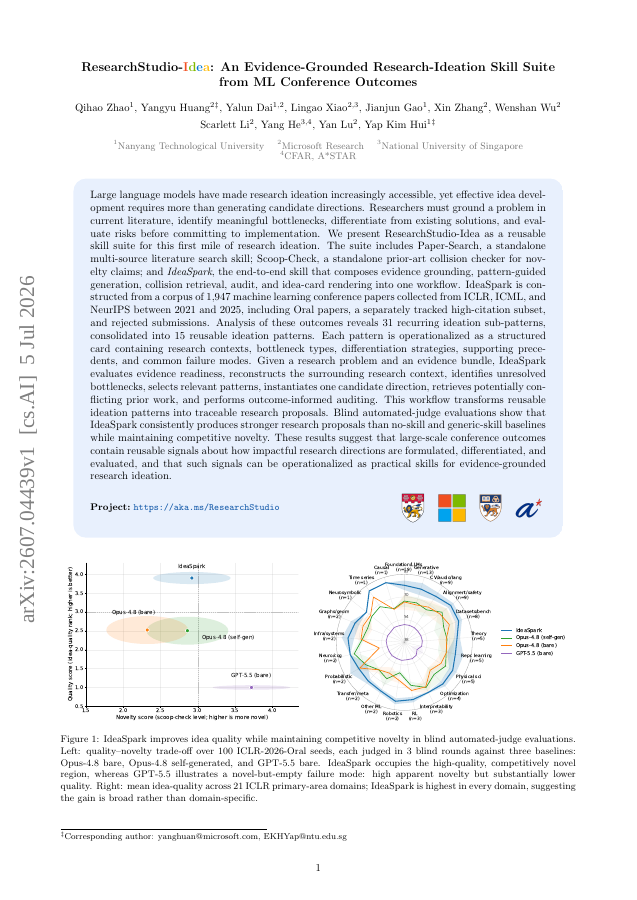
Large language models have made research ideation increasingly accessible, yet effective idea development requires more than generating candidate directions. Researchers must ground a problem in current literature, identify meaningful bottlenecks, differentiate from existing…
Generalist robot manipulation policies have advanced rapidly, yet existing benchmarks remain limited in systematically evaluating their capabilities. Many rely on simple, short-horizon, or skill-narrow tasks with limited capability coverage, and are often conducted only in…

Diffusion large language models (dLLMs) generate text by iteratively denoising a masked sequence, offering a parallel alternative to autoregressive models, but eliciting strong reasoning through post-training remains difficult: supervised fine-tuning is off-policy and suffers…

Recent advances in multimodal foundation models and agent systems have driven GUI agents from single-platform task execution toward cross-platform interaction. However, building multi-platform GUI agents remains challenging.

Unsupervised syllabic tokenization aims to learn discrete syllabic tokens that capture latent linguistic content-related structure from raw speech. Recent syllabic tokenization methods employ teacher-student distillation of the pretrained HuBERT to organize latent speech frame…

A key challenge in Arabic NLP is the scarcity of dialectal data relative to Modern Standard Arabic (MSA), causing LLMs to overproduce MSA and struggle with dialectally accurate generation.

Concept erasure aims to remove a target concept from a representation while preserving the other information encoded in it. This is difficult because representations encode many concepts that are often correlated with the erasure target, so removing the target risks damaging…

Pixel-wise Earth-observation (EO) foundation models are now achieving state-of-the-art performance via generated spatial embeddings. However, how these models scale and how best to spend a pretraining budget remain poorly understood.

Optimizer selection for large-scale model training has become a system-level design decision constrained jointly by compute, memory, tuning budget, and task diversity, yet the landscape of over one hundred methods remains fragmented.

Challenges remain in ego-centric 3D scene generation due to limited view overlap and the dominant influence of individual perspectives on scene interpretation. These factors hinder the creation of viewpoint-consistent and semantically aligned visual content, as well as the…

Unified multi-modal models (UMMs) have shown promising interleaved text-image reasoning capabilities, yet effectively optimizing such multi-turn generation via reinforcement learning (RL) remains an open challenge.

Long-horizon behavior prediction aims to infer a user's next action based on a lengthy historical sequence, playing a crucial role in artificial intelligence field. The rise of large language models (LLMs) offers a promising direction for sequential behavior prediction, yet LLMs…

Crossmodal correspondences between sound and taste are well established in psychology and neuroscience, but largely absent from content-based multimedia retrieval. We formalise taste-from-audio prediction as a content-based music information retrieval benchmark over a…

We introduce Vidu S1, a real-time interactive video generation model supporting voice control of digital characters. Users can control video generation content at any moment through voice instructions.

While skill optimization for autonomous agents has gained traction, existing methods rely on complex pipelines. This leaves a fundamental question unaddressed: What constitutes a minimal viable pipeline for skill optimization, where every component is justified by theory or…

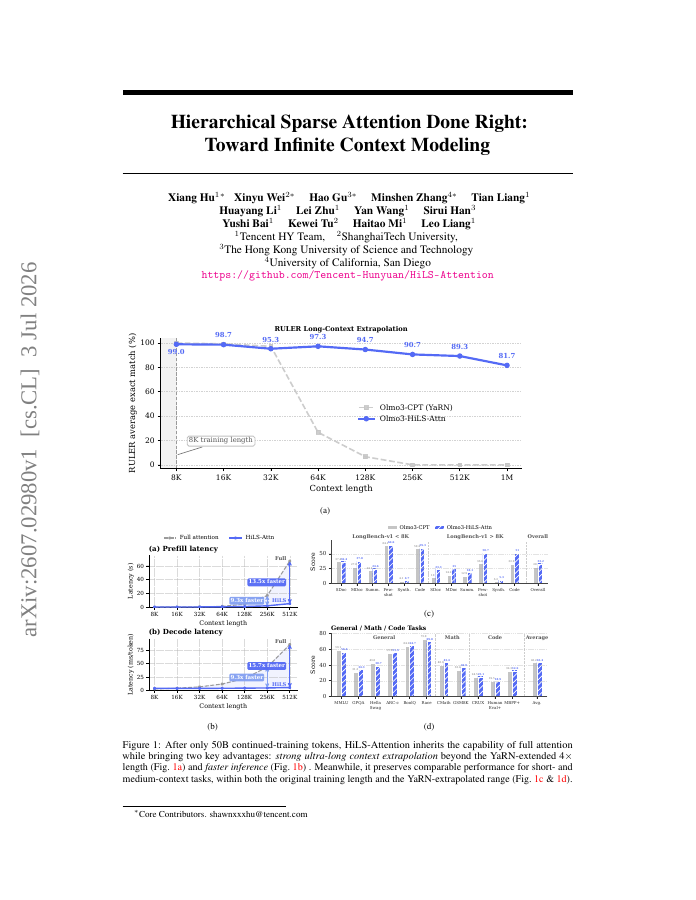
Scaling modern large language models (LLMs) to long contexts is limited by the quadratic computation cost, and poor length extrapolation of dense attention. Chunk-wise sparse attention offers a promising alternative, but all existing methods fall short of full attention because…
Dense video captioning aims to generate temporally grounded descriptions of video events, benefiting both event-level video understanding and generation. In this domain, autoregressive video large language models have emerged as a prevalent paradigm due to their strong…

We introduce Gemma 4, a new generation of open-weight, natively multimodal language models in the Gemma model family. Designed to advance compute efficiency and reasoning, the Gemma 4 model suite features dense and Mixture-of-Experts architectures, ranging from 2.3B to 31B…

Vision-Language-Action (VLA) models are fundamentally bottlenecked by the scarcity of expert demonstrations -- triplets of observations, instructions, and actions that are costly to collect at scale.

Vision-Language Models (VLMs) have demonstrated immense promise in Spatio-Temporal Video Grounding (STVG). However, current evaluation protocols are largely confined to zero-shot assessments on general, daily-life benchmarks.

LLM agents increasingly perform autonomous actions through external tools, leading to complex and evolving safety risks. However, existing safety testing targets expert-designed safety violations, and the corresponding outcomes are evaluated by hard-coded rules, making them…

Foundation models are routinely released to the public, yet the data recipes used to train them -- such as domain mixture weights that determine how different sources are sampled -- are rarely disclosed.

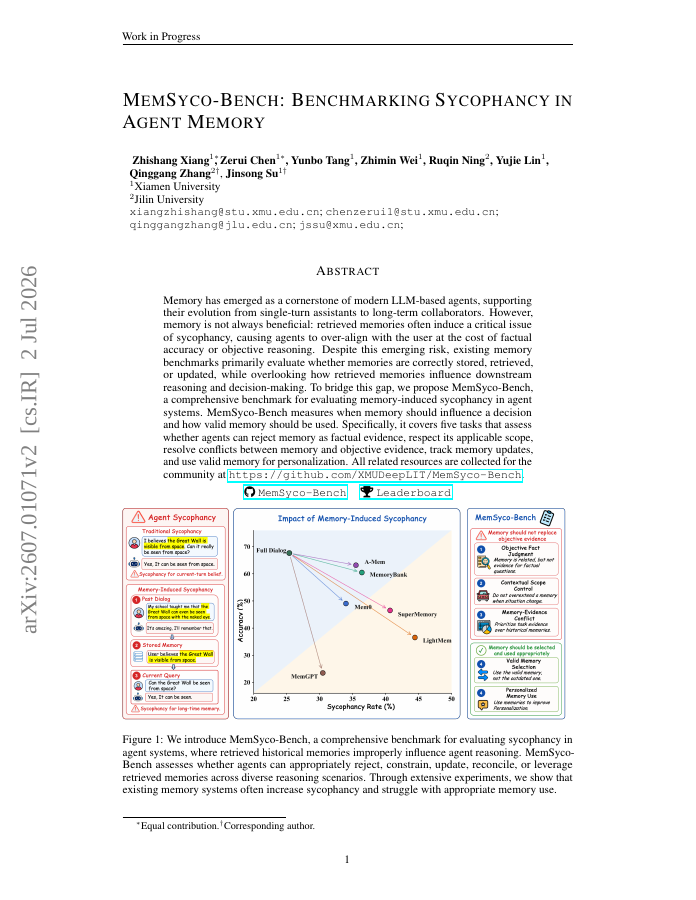
Memory has emerged as a cornerstone of modern LLM-based agents, supporting their evolution from single-turn assistants to long-term collaborators. However, memory is not always beneficial: retrieved memories often induce a critical issue of sycophancy, causing agents to…
Many everyday programming tasks resist clean rule-based implementation, such as alerting on important log lines, repairing malformed JSON, or ranking search results by intent, and are increasingly outsourced to large language model APIs at the cost of locality, reproducibility,…

Memory for a long-horizon LLM agent is a contract about what each future decision is allowed to see. The simplest contract appends past observations, tool calls, and reflections to every prompt, which makes prior context easy to access but also turns it into a jumbled mixture in…

Evaluating LLM agents on benchmarks like SWE-Bench and GAIA can be expensive, time-consuming, and requires complex infrastructure. A single evaluation can cost thousands of dollars and take days to complete.
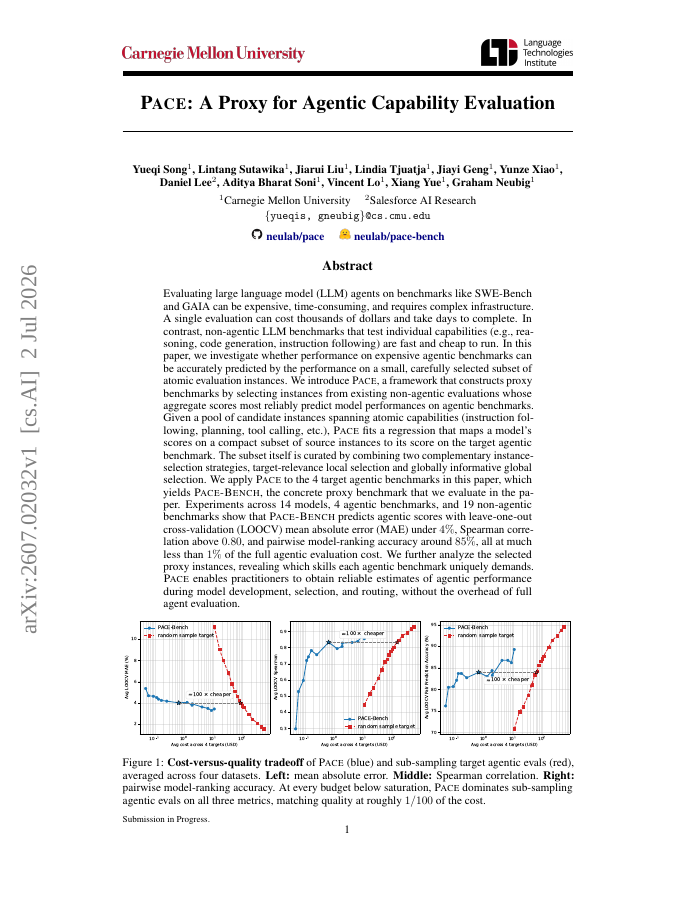
Continual post-training enables foundation models to acquire new knowledge while preserving existing capabilities. Recent work suggests that on-policy learning can mitigate forgetting, with on-policy self-distillation emerging as a particularly attractive approach.

Data science aims to derive actionable insights from heterogeneous raw data, unlocking the value of the massive amounts of data generated in modern society. Automating this process is essential to reducing labor-intensive efforts for data scientists and enabling scalable…

We present RuleChef, a framework that uses large language models (LLMs) to generate executable rules for NLP tasks such as text classification, Named Entity Recognition (NER), or relation extraction.

Grid-based approaches to approximate nearest neighbor (ANN) search have been absent from modern scaling analyses. We present a systematic characterization of a multiprobe grid algorithm with respect to dataset size $N$ and dimensionality $d$.

Vision-language pretraining remains dominated by contrastive objectives, whereas vision-only self-supervised learning has largely adopted non-contrastive methods. At the same time, the role of vision-language encoders has shifted: they are increasingly deployed not as zero-shot…

LLMs are increasingly used to brainstorm research ideas, but existing evaluations mostly judge individual ideas by novelty, feasibility, or expert preference. We instead ask: how far are current LLM-generated ideas from human researchers? To characterize this gap, we build a…

Memory expertise is a learned skill: knowing what to encode, when to retrieve, and how to organize knowledge--a capacity known in cognitive science as metamemory. We bring this perspective to LLMs by treating memory management as a trainable skill.

Scientific literature search often requires more than retrieving papers from a single query: users' intents are underspecified, preference-dependent, and evolve through interaction.

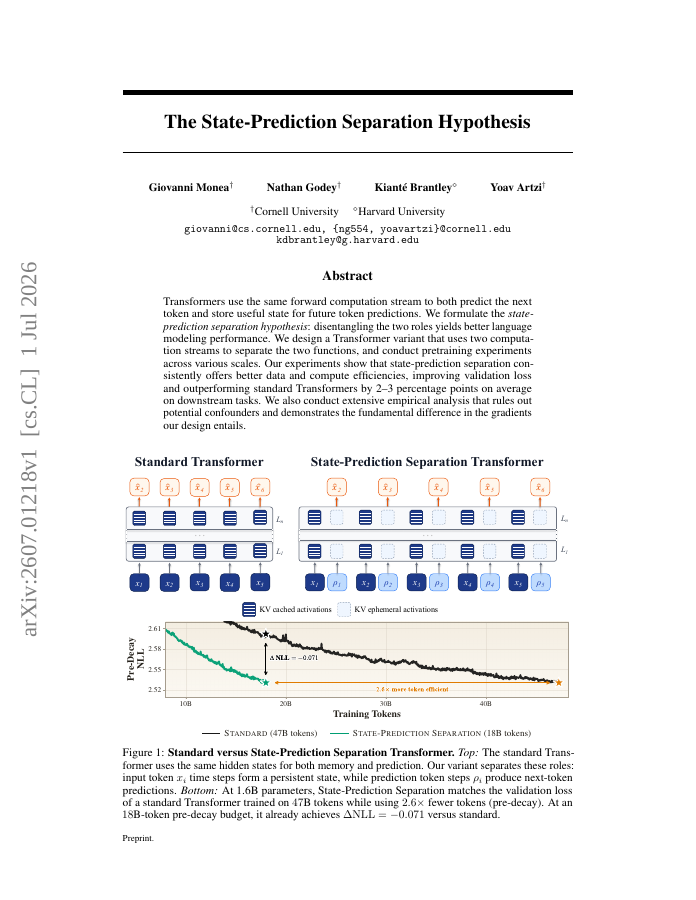
Transformers use the same forward computation stream to both predict the next token and store useful state for future token predictions. We formulate the \emph{state-prediction separation hypothesis}: disentangling the two roles yields better language modeling performance.
We introduce TiRex-2, a recurrent xLSTM-based time series foundation model that generalizes the univariate TiRex to multivariate forecasting with both past and future covariates.

Accelerating materials discovery requires AI systems that can generate scientifically valid hypotheses through multi-step, domain-grounded reasoning. Standard large language models often produce fluent but weakly traceable responses to open-ended materials design problems,…

World models can enable Model Predictive Control (MPC), but this requires dynamics prediction that is both fast enough for online use and expressive enough to represent uncertain futures.

Vision-Language-Action (VLA) models often fail to perform the same learned tasks under environmental shifts, such as changes in camera pose and shifts to a different but similar robot (e.g., from Panda to UR5e).

As video corpora continue to expand in both scale and task complexity, there is increasing demand for approaches that retrieve relevant videos from large-scale corpora (inter-video reasoning) and subsequently perform fine-grained, query-conditioned tasks (intra-video reasoning)…

Three of the most popular methods for training language models to reason look like three different tricks. They are not. All three adjust a single number: standard deviation, reflecting how much a prompt's sampled answers disagree.

Recent multimodal large language models have shown great promise in clinical image reasoning, but existing post-training pipelines remain predominantly outcome-centric, relying on final answer correctness or sequence-level preferences.

Metacognition is a critical component of intelligence that describes the ability to monitor and regulate one's own cognitive processes. Yet LLMs exhibit systemic deficiencies in key metacognitive faculties: they hallucinate with high confidence, fail to recognize knowledge…

While large language models (LLMs) perform well on table tasks, they still make data referencing errors (DREs), i.e., incorrectly citing or omitting table values, despite understanding the table structure.

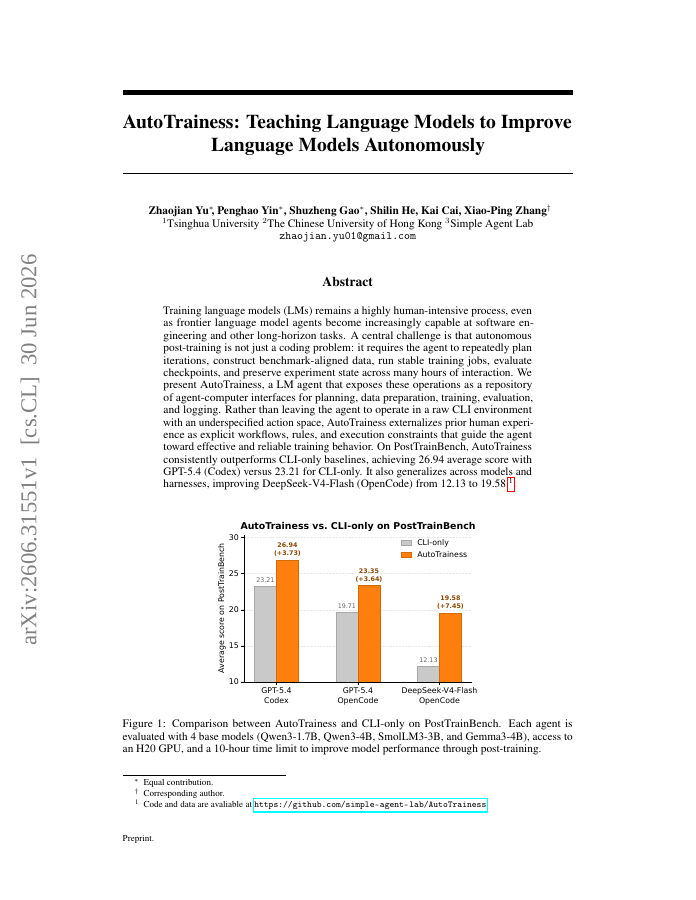
Training language models (LMs) remains a highly human-intensive process, even as frontier language model agents become increasingly capable at software engineering and other long-horizon tasks.
Speculative decoding accelerates inference by using a lightweight draft model to generate candidate tokens in parallel, and are then verified by the target model, enabling lossless acceleration.

Large language models increasingly operate over long contexts, where the KV cache becomes a dominant memory bottleneck: its size grows linearly with sequence length and must be retained throughout decoding, making full GPU caching prohibitively expensive without compression.

LLM agents increasingly act over long horizons, where a single trajectory can contain hundreds or thousands of actions. In these settings, outcome-only rewards provide too sparse guidance, failing to inform the model about the goodness of intermediate actions.

Hierarchical Vision-Language-Action (VLA) models decouple high-level planning from low-level control to improve generalization in robot manipulation. Recent work in this paradigm uses 2D end-effector trajectories predicted by a Vision-Language Model (VLM) as explicit guidance…

As AI agents become increasingly capable of complex, long-horizon reasoning, rigorous and holistic evaluation is essential for measuring progress toward real-world healthcare applications.

Current operating systems expose interfaces optimized for human users but not for AI agents. Humans benefit from pixels, icons, windows, visual grouping, mouse movement, and keyboard shortcuts; AI agents instead need compact semantic state, grounded actions, and reliable…

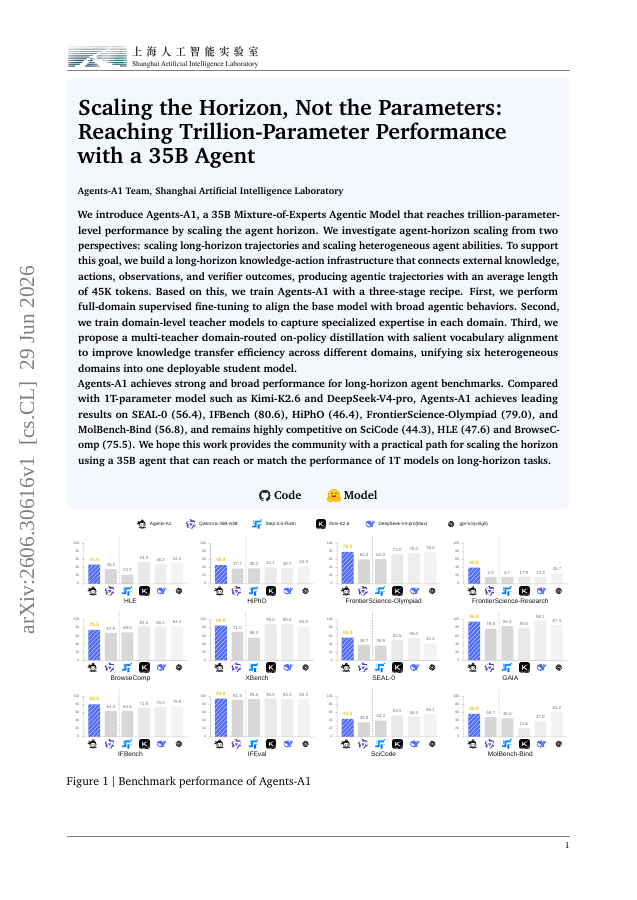
We introduce Agents-A1, a 35B Mixture-of-Experts Agentic Model that reaches trillion-parameter-level performance by scaling the agent horizon. We investigate agent-horizon scaling from two perspectives: scaling long-horizon trajectories and scaling heterogeneous agent abilities.
Hybrid attention models improve long-context efficiency by retaining only a subset of full-attention layers and replacing the remaining layers with linear attention. However, the effectiveness of Transformer-to-hybrid conversion critically depends on which layers preserve full…

We introduce SWE-Interact, a new testbed for evaluating coding agents on multi-turn, interactive, user-driven software engineering tasks. Existing frontier SWE benchmarks typically provide complete requirements upfront and evaluate agents on autonomous implementation.

On-policy distillation (OPD) offers superior capacity transfer by supervising student-sampled trajectories with dense token-level signals. To furnish high-quality supervision sources and thereby elevate the performance frontier of distillation, an intuitive direction is to…

Generative molecular design is shaped by simple proxy benchmarks for drug-like properties and models pretrained on large pharmaceutical datasets. This combination yields strong benchmark metrics but limits transferability to domains structurally distinct from drug discovery.

Embodied agents are typically built as hand-designed compositions of perception, memory, planning, and action modules. This modularity exposes a large architectural design space, but current systems still rely on researcher intuition to choose where information is stored, how…

While large language models have been dominating the research landscape recently, small language models remain highly relevant across various domains; yet, they receive far less attention.

Most coding-agent benchmarks are static: an agent receives a complete task description up front and is judged only by its final code. Real coding assistance is interactive, with users clarifying goals, adding constraints, and correcting mistakes over multiple turns.

In real-world applications, guardrails are often expected to identify unsafe user-model interactions according to application-specific safety policies, rather than relying on predefined risk taxonomies.

Data, as the fundamental substrate of modern intelligence, has greatly driven the development of current foundation models. Naturally, researchers aim to extend this paradigm to the domain of GUI agents, hoping to build strong GUI agents through a similar paradigm.

The materials science literature encodes decades of experimental knowledge in figures, yet this visual record remains locked away and inaccessible to AI at scale. The core difficulty is structural: most scientific figures are compound, with a single caption describing multiple…

Block Diffusion Language Models (BD-LMs) improve diffusion-based text generation with KV caching and flexible-length generation. A natural next step is to extend them from Single-Block Diffusion (SingleBD) to Multi-Block Diffusion (MultiBD), where a running-set of consecutive…

A faithful 3D world representation should account for layered geometry, where a single camera ray may contain multiple visible and geometrically valid surfaces. Monocular depth estimation, however, reduces this structure to one scalar depth per pixel.

Existing computer-use benchmarks fail to capture the realism, complexity, and long-horizon demands of real-world computer use, limiting their ability to reveal the limitations of frontier agents.

Vision-language dataset distillation (VLDD) compresses a large image-text paired dataset into a small set of synthetic pairs that can efficiently train contrastive vision-language models under strict data and compute budgets.

Video understanding is a fundamental capability for multimodal intelligence, and recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance on Video Question Answering (VideoQA) benchmarks.

Large language models (LLMs) are increasingly used to take actions in the real world and support human decision-making, yet most agents rely on parametric knowledge, fixed post-training data, retrieval, or search.

LLM agents handle user requests on behalf of organizations through tool calls and must follow the company policies stated in their system prompts. Prior work approaches this as a safeguarding problem -- external checks that block non-compliant agent actions.

Would experience designing faster GPU kernels also help close in on a long-standing open mathematical conjecture? Large Language Models (LLMs) integrated into evolutionary search have recently produced state-of-the-art solutions on optimization tasks, including open mathematical…

LLM agents are expected to act over multiple turns, using search, browsing interfaces, and terminal tools to complete user goals. Yet not every goal is well specified or achievable in the available environment.

People overthink; language models over-sample, and the extra effort can talk both into a worse answer. Reasoning systems answer a hard question by sampling it many times (test-time scaling), and the more they draw, the more often a correct answer turns up somewhere, so coverage,…

The fastest, most cost-efficient tier of OpenAI's GPT-5.6 family, available in limited preview through the OpenAI API and Codex for approved organizations.
The capable, lower-cost tier of OpenAI's GPT-5.6 family, available in limited preview through the OpenAI API and Codex for approved organizations.
OpenAI's GPT-5.6 flagship, available in limited preview through the OpenAI API and Codex for approved organizations.
Building performant Vision-Language Models (VLMs) requires carefully curating large-scale training datasets, yet the community lacks systematic benchmarks for evaluating such curation strategies.

As large language models and harness frameworks continue to advance, agents operating in terminals are increasingly capable of performing a broader range of general computer-use tasks beyond coding.

Predicting human item difficulty is central to educational assessment, where reliable estimates support fairness and effective test construction. Existing methods often depend on costly human calibration or item-level textual representations, providing limited evidence about the…

Language models (LMs) represent tokens using embedding matrices that scale linearly with the vocabulary size. To constrain the parameter footprint, prior work proposes hashing many tokens into a single vector within encoder-only models.

Pixel-space continuous-token autoregressive (AR) generation directly models images as sequences of raw pixel patches, avoiding discrete tokenization or a separately pretrained tokenizer.

Claude Fable 5 is Anthropic's most capable widely released model, built for the most demanding reasoning and long-horizon agentic work. Shares its base model with the invitation-only Claude Mythos 5.
Qwen3.7Plus is an AI model from Alibaba.
Claude Opus 4.8 (Adaptive Reasoning, Max Effort) is an AI model from Anthropic.
PhysGym Arena DR-hard benchmark for domain-randomized Gym simulator repair
PhysGym Arena medley benchmark for achievable medium-hard Gym simulator repair
MiniCPM5-1B (Non-reasoning) is an AI model from OpenBMB.
Command A+ is an AI model from Cohere.
Qwen3.7Max is an AI model from Alibaba.
Gemini 3.5 Flash is an AI model from Google (Alphabet Inc.).
JT-35B-Flash is an AI model from China Mobile.
MathArena Apex Shortlist final-answer evaluation environment
Multi-turn DevOps troubleshooting environment with simulated diagnostic tools
MiniCPM-V 4.6 1.3B is an AI model from OpenBMB.
Evaluates LLM explanations of textbook excerpts across pedagogy dimensions including concept coverage, coherence, prerequisite ordering, and origin...
Science Sim chemistry compound and reaction screening environment
Science Sim materials candidate ranking and simulation planning environment
Science Sim computational biology protein-variant decision environment
Ring-2.6-1T is an AI model from InclusionAI.
Polars DataFrame manipulation environment for training and evaluation
AR Credit Command Post Evals by Cognida.ai: enterprise mock-ERP credit hold and order release for AR automation agents (structured data only).
GPT-5.5 Instant (May 2026) is an AI model from OpenAI.
Crystal relaxation environment for RLM training, with multiple rubrics including format, composition, bond lengths, and formation energy.
A self-growing toolbench environment - early signs of self-improving agentic capability
Grok 4.3 is an AI model from xAI.
Granite 4.1 3B is an AI model from Ibm.
Granite 4.1 30B is an AI model from Ibm.
Nemotron 3 Nano Omni 30B A3B Reasoning is an AI model from NVIDIA.
Mistral Medium 3.5 is an AI model from Mistral AI.
granite-4.1-8b is an AI model from Ibm, released with open weights.
Long-horizon physical-AI benchmark with dense Gemini rewards
DeepSeek V4 Flash is an AI model from DeepSeek, released with open weights.
DeepSeek's April 2026 next-gen open-weights flagship - 1.6T-total / 49B-active MoE with 1M context and DeepSeek Sparse Attention.
LongCoT long-horizon reasoning evaluation environment using RLM with Python REPL
Ling-2.6-1T is an AI model from InclusionAI.
Hy3-preview is an AI model from Tencent.
GPT-5.5 is an AI model from OpenAI.
Qwen3.6 27B is an AI model from Alibaba.
MiMo-V2.5 is an AI model from Xiaomi.
mimo-v2.5-pro is an AI model from Xiaomi, released with open weights.
kimi-k2.6 is an AI model from Moonshot AI.
Qwen3.6 Max Preview is an AI model from Alibaba.
Claude Opus 4.7 is an AI model from Anthropic.
muse-spark is an AI model from Meta Platforms.
GLM-5.1 is an AI model from Zai, released with open weights.
Qwen3.6Plus is an AI model from Alibaba.
minimax-m2.7 is an AI model from Minimax.
GPT-5.4 nano is an AI model from OpenAI.
GPT-5.4 mini is an AI model from OpenAI.
Grok 4.20 0309 is an AI model from xAI.
GPT-5.4 is an AI model from OpenAI.
Gemini 3.1 Flash-Lite is an AI model from Google (Alphabet Inc.).
Gemini 3.1 Pro Preview is an AI model from Google (Alphabet Inc.).
Claude Sonnet 4.6 is an AI model from Anthropic.
Claude Opus 4.6 is an AI model from Anthropic.
Qwen3 Coder Next is an AI model from Alibaba.
Gemini 3 Flash Preview (Reasoning) is an AI model from Google (Alphabet Inc.).
GPT-5.2 is an AI model from OpenAI.
DeepSeek V3.2 is an AI model from DeepSeek, released with open weights.
Claude Opus 4.5 is an AI model from Anthropic.
Grok 4.1 Fast is an AI model from xAI.
Gemini 3 Pro Preview (low) is an AI model from Google (Alphabet Inc.).
GPT-5.1 is an AI model from OpenAI.
Claude 4.5 Haiku is an AI model from Anthropic.
anthropic/claude-sonnet-4.5 is an AI model.
Gemini 2.5 Flash Preview (Sep '25) (Non-reasoning) is an AI model from Google (Alphabet Inc.).
Gemini 2.5 Flash-Lite Preview (Sep '25) is an AI model from Google (Alphabet Inc.).
Grok 4 Fast is an AI model from xAI.
Alibaba's >1T-parameter dense Qwen3 flagship, available only as a closed API on Qwen Chat and Alibaba Cloud.
Nous Research's mid-size hybrid-reasoning post-training of Llama-3.1-70B with switchable <think> mode and JSON-schema-faithful outputs.
Gemma 3 270M is an AI model from Google (Alphabet Inc.).
OpenAI's August 2025 unified frontier model that auto-routes between a fast model and a deeper "thinking" variant.
GPT-5 mini is an AI model from OpenAI.
GPT-5 nano is an AI model from OpenAI.
Claude 4.1 Opus is an AI model from Anthropic.
Qwen3 Coder 30B A3B Instruct is an AI model from Alibaba.
A comprehensive evaluation benchmark designed to assess language models' medical capabilities across a wide range of healthcare scenarios.
Qwen3.30B A3b Instruct 2507 is an AI model from Alibaba, released with open weights.
Sierra's dual-control extension of τ-bench - now the user is also an LLM and both agents share access to the same tool-driven environment.
Gemini 2.5 Pro is an AI model from Google (Alphabet Inc.).
Claude 4 Sonnet is an AI model from Anthropic.
Gemini 2.5 Flash is an AI model from Google (Alphabet Inc.).
Qwen3 0.6B is an AI model from Alibaba.
Qwen3 30B A3B is an AI model from Alibaba.
Qwen3 14B is an AI model from Alibaba.
o4 Mini is an AI model from OpenAI.
OpenAI's first true "reasoning at scale" model, announced Dec 2024 and publicly released April 2025, which crossed human-expert ceiling on GPQA.
Phi-4-mini-instruct is an AI model, released with open weights.
2,500 expert-authored questions across math, sciences, and humanities designed to be the hardest closed-ended benchmark for frontier models.
First open training environment for real-world software-engineering agents - 2,438 Python tasks from 11 repos, each with an executable runtime and a hidden test suite.
Assesses whether AI agents might engage in harmful activities by testing their responses to malicious prompts in areas like cybercrime, harassment, and fraud, aiming to ensure safe behavior.
Llama-3.2-1B is an AI model with 1.0B parameters, released with open weights.
Llama-3.2-3B is an AI model with 3.0B parameters, released with open weights.
Qwen2.5-1.5B-Instruct is an AI model with 1.5B parameters, released with open weights.
Qwen2.5-3B-Instruct is an AI model with 3.0B parameters, released with open weights.
Qwen2.5-14B-Instruct is an AI model with 14.0B parameters, released with open weights.
Qwen2.5-7B is an AI model with 7.0B parameters, released with open weights.
Llama-3.1-8B is an AI model with 8.0B parameters, released with open weights.
Multi-turn customer-service simulation testing whether agents follow domain policies while interacting with a tool-using user simulator.
Meta-Llama-3-8B-Instruct is an AI model with 8.0B parameters, released with open weights.
ServiceNow's unified Gym-style framework for web agents - wraps WebArena, MiniWoB, VisualWebArena, WorkArena, AssistantBench, WebLINX, and more under one Playwright-backed interface.
Mistral-7B-Instruct-v0.2 is an AI model with 7.0B parameters, released with open weights.
Graduate-level physics, chemistry, and biology multiple-choice questions written by PhDs and verified to be Google-proof.
500 prompts with verifiable instruction-following constraints (word counts, casing, JSON format) checked by deterministic rules - no LLM judge needed.
LMSYS's automated pipeline for distilling high-quality LLM benchmarks from crowdsourced chat data (e.g. Chatbot Arena, WildChat), producing the Arena-Hard-Auto benchmark.
Cleaned, human-validated subset of OSWorld tasks designed for stable cross-lab comparison of computer-use agents.
Allen AI's flagship open SFT mixture combining new persona-driven prompts with curated public data for post-training a frontier-quality instruct model.
Anthropic's foundational helpful-and-harmless human preference dataset - the first major public RLHF corpus and a long-time community baseline.
974 short crowd-sourced Python tasks with three unit tests each, used alongside HumanEval as a baseline code-generation benchmark.
164 hand-written Python programming problems with unit tests, the original LLM code-generation benchmark from OpenAI's Codex paper.
Aligned text-and-3D embodied environment - agents learn household tasks (pick & place, heat, cool, clean) as both TextWorld games and visually-rendered ALFRED scenes.