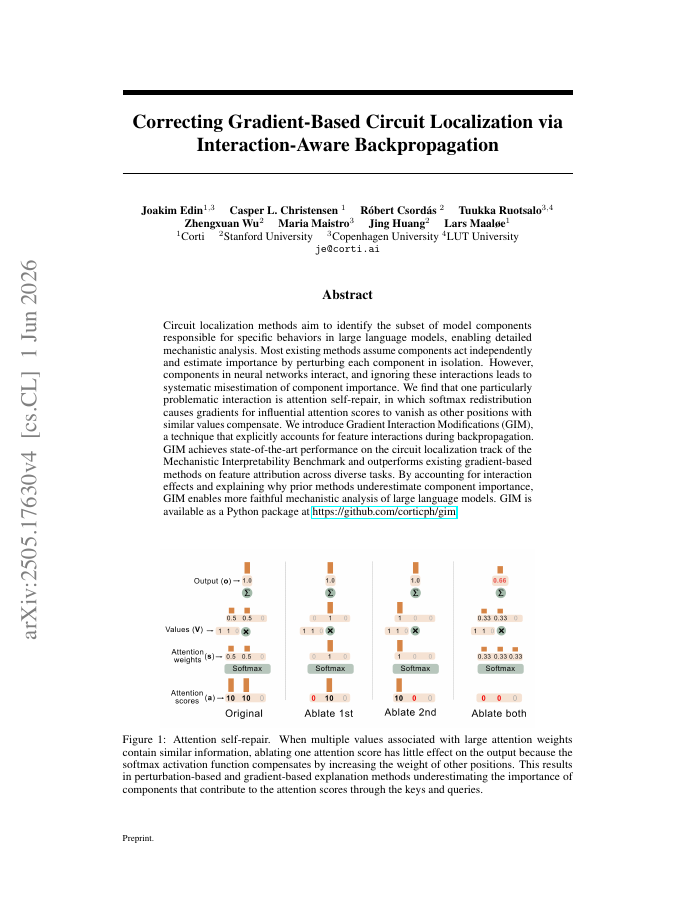
Circuit localization methods aim to identify the subset of model components responsible for specific behaviors in large language models, enabling detailed mechanistic analysis. Most existing methods assume components act independently and estimate importance by perturbing each component in isolation. However, components in neural networks interact, and ignoring these interactions leads to systematic misestimation of component importance. We find that one particularly problematic interaction is attention self-repair, in which softmax redistribution causes gradients for influential attention scores to vanish as other positions with similar values compensate. We introduce Gradient Interaction Modifications (GIM), a technique that explicitly accounts for feature interactions during backpropagation. GIM achieves state-of-the-art performance on the circuit localization track of the Mechanistic Interpretability Benchmark and outperforms existing gradient-based methods on feature attribution across diverse tasks. By accounting for interaction effects and explaining why prior methods underestimate component importance, GIM enables more faithful mechanistic analysis of large language models. GIM is available as a Python package at https://github.com/corticph/gim.
Correcting Gradient-Based Circuit Localization via Interaction-Aware Backpropagation
Circuit localization methods aim to identify the subset of model components responsible for specific behaviors in large language models, enabling detailed mechanistic analysis.
- Preview
- Year
- 2025
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2505.17630CC-BY-4.0
- TL;DR
- Semantic Scholar