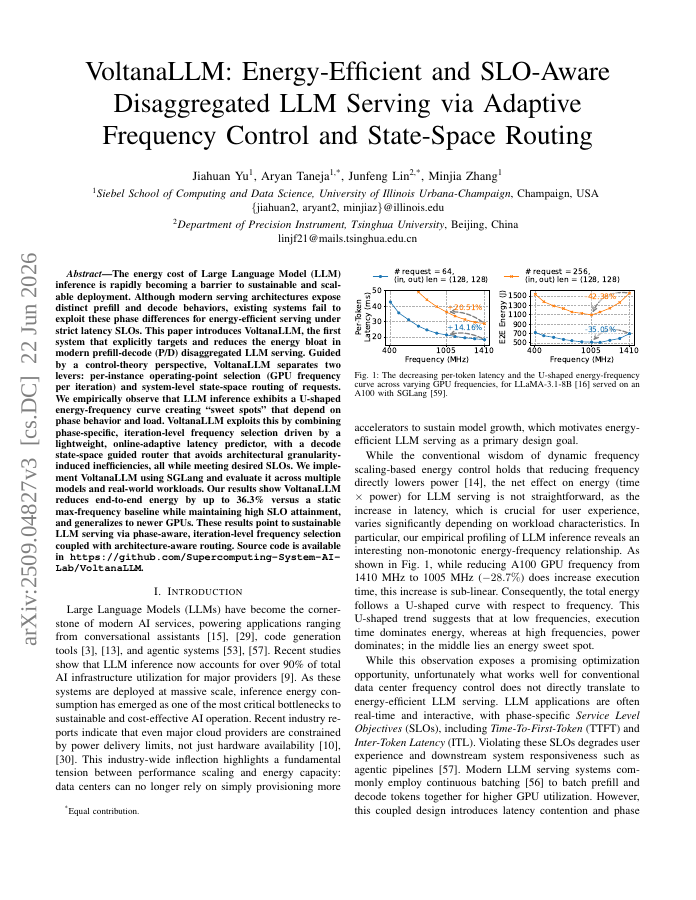
The energy cost of Large Language Model (LLM) inference is rapidly becoming a barrier to sustainable and scalable deployment. Although modern serving architectures expose distinct prefill and decode behaviors, existing systems fail to exploit these phase differences for energy-efficient serving under strict latency SLOs. This paper introduces VoltanaLLM, the first system that explicitly targets and reduces the energy bloat in modern prefill-decode (P/D) disaggregated LLM serving. Guided by a control-theory perspective, VoltanaLLM separates two levers: per-instance operating-point selection (GPU frequency per iteration) and system-level state-space routing of requests. We empirically observe that LLM inference exhibits a U-shaped energy-frequency curve creating "sweet spots" that depend on phase behavior and load. VoltanaLLM exploits this by combining phase-specific, iteration-level frequency selection driven by a lightweight, online-adaptive latency predictor, with a decode state-space guided router that avoids architectural granularity-induced inefficiencies, all while meeting desired SLOs. We implement VoltanaLLM using SGLang and evaluate it across multiple models and real-world workloads. Our results show VoltanaLLM reduces end-to-end energy by up to 36.3% versus a static max-frequency baseline while maintaining high SLO attainment, and generalizes to newer GPUs. These results point to sustainable LLM serving via phase-aware, iteration-level frequency selection coupled with architecture-aware routing. Source code is available in https://github.com/Supercomputing-System-AI-Lab/VoltanaLLM.
VoltanaLLM: Energy-Efficient and SLO-Aware Disaggregated LLM Serving via Adaptive Frequency Control and State-Space Routing
The energy cost of Large Language Model (LLM) inference is rapidly becoming a barrier to sustainable and scalable deployment. Although modern serving architectures expose distinct prefill and decode behaviors, existing systems fail to exploit these phase differences for…
- Preview
- Year
- 2025
- Hosting
- Excerpt onlyCC-BY-NC-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2509.04827CC-BY-NC-4.0
- TL;DR
- Semantic Scholar