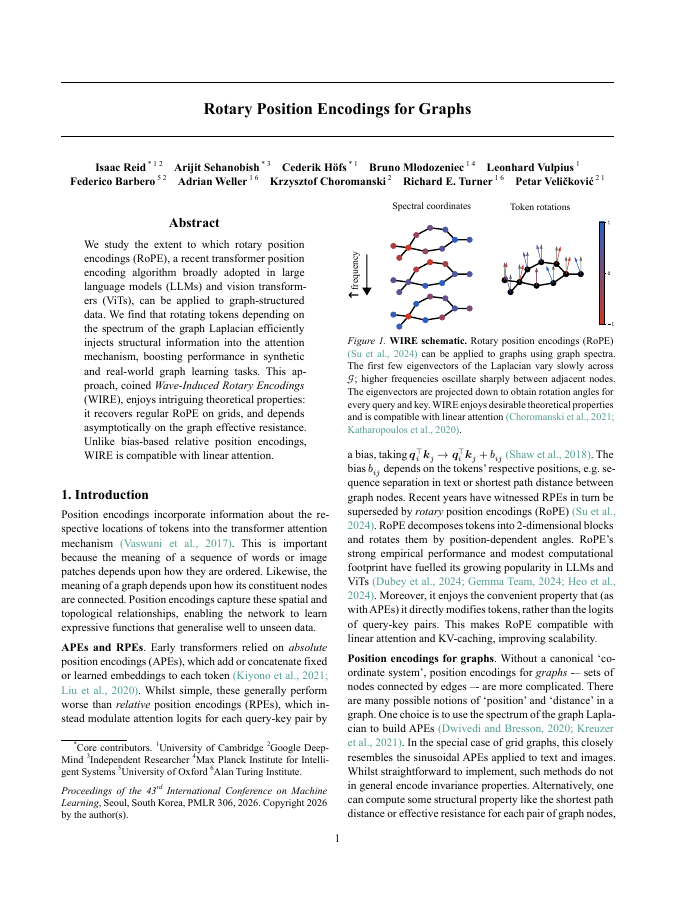
We study the extent to which rotary position encodings (RoPE), a recent transformer position encoding algorithm broadly adopted in large language models (LLMs) and vision transformers (ViTs), can be applied to graph-structured data. We find that rotating tokens depending on the spectrum of the graph Laplacian efficiently injects structural information into the attention mechanism, boosting performance in synthetic and real-world graph learning tasks. This approach, coined Wave-Induced Rotary Encodings (WIRE), enjoys intriguing theoretical properties: it recovers regular RoPE on grids, and depends asymptotically on the graph effective resistance. Unlike bias-based relative position encodings, WIRE is compatible with linear attention.
Rotary Position Encodings for Graphs
We study the extent to which rotary position encodings (RoPE), a recent transformer position encoding algorithm broadly adopted in large language models (LLMs) and vision transformers (ViTs), can be applied to graph-structured data.
- Preview
- Year
- 2025
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2509.22259CC-BY-4.0
- TL;DR
- Semantic Scholar