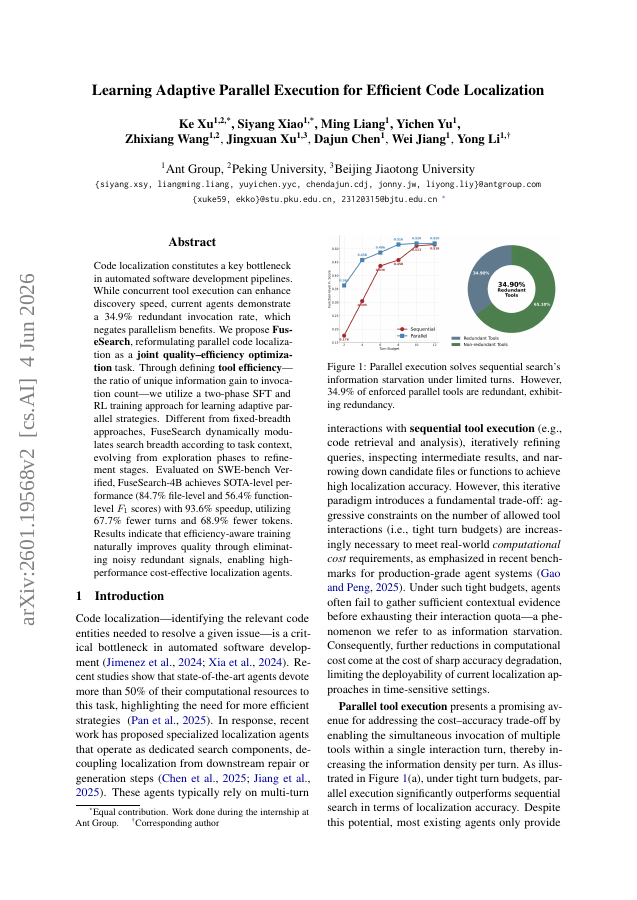
Code localization constitutes a key bottleneck in automated software development pipelines. While concurrent tool execution can enhance discovery speed, current agents demonstrate a 34.9% redundant invocation rate, which negates parallelism benefits. We propose FuseSearch, reformulating parallel code localization as a joint quality-efficiency optimization} task. Through defining tool efficiency -- the ratio of unique information gain to invocation count -- we utilize a two-phase SFT and RL training approach for learning adaptive parallel strategies. Different from fixed-breadth approaches, FuseSearch dynamically modulates search breadth according to task context, evolving from exploration phases to refinement stages. Evaluated on SWE-bench Verified, FuseSearch-4B achieves SOTA-level performance (84.7% file-level and 56.4% function-level F1 scores) with 93.6% speedup, utilizing 67.7% fewer turns and 68.9% fewer tokens. Results indicate that efficiency-aware training naturally improves quality through eliminating noisy redundant signals, enabling high-performance cost-effective localization agents.
Learning Adaptive Parallel Execution for Efficient Code Localization
Code localization constitutes a key bottleneck in automated software development pipelines. While concurrent tool execution can enhance discovery speed, current agents demonstrate a 34.9% redundant invocation rate, which negates parallelism benefits.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2601.19568CC-BY-4.0
- TL;DR
- Semantic Scholar