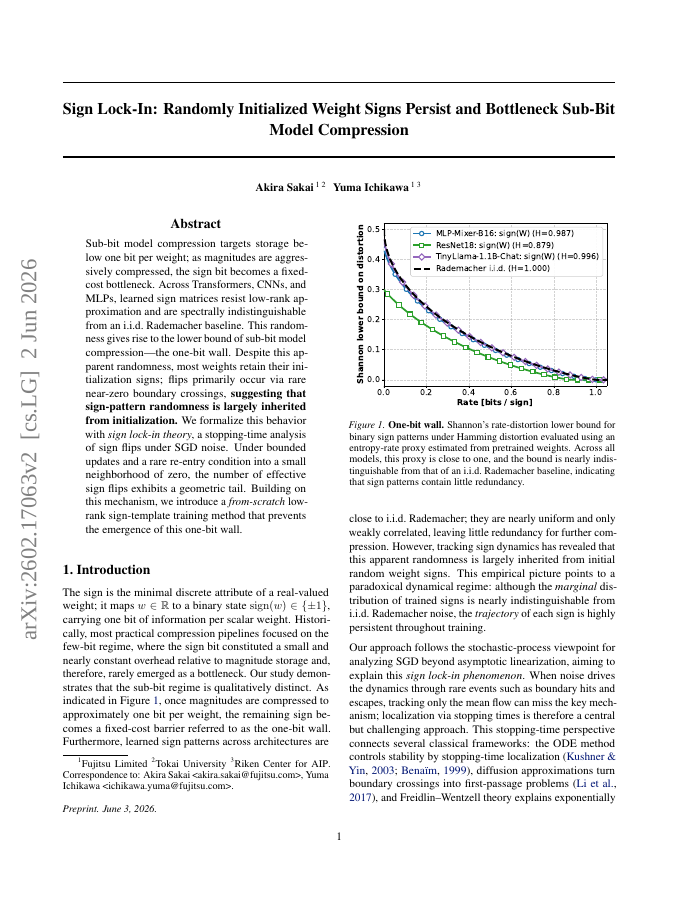
Sub-bit model compression targets storage below one bit per weight; as magnitudes are aggressively compressed, the sign bit becomes a fixed-cost bottleneck. Across Transformers, CNNs, and MLPs, learned sign matrices resist low-rank approximation and are spectrally indistinguishable from an i.i.d. Rademacher baseline. This randomness gives rise to the lower bound of sub-bit model compression -- the one-bit wall. Despite this apparent randomness, most weights retain their initialization signs; flips primarily occur via rare near-zero boundary crossings, suggesting that sign-pattern randomness is largely inherited from initialization. We formalize this behavior with sign lock-in theory, a stopping-time analysis of sign flips under SGD noise. Under bounded updates and a rare re-entry condition into a small neighborhood of zero, the number of effective sign flips exhibits a geometric tail. Building on this mechanism, we introduce a from-scratch low-rank sign-template training method that prevents the emergence of this one-bit wall.
Sign Lock-In: Randomly Initialized Weight Signs Persist and Bottleneck Sub-Bit Model Compression
Sub-bit model compression targets storage below one bit per weight; as magnitudes are aggressively compressed, the sign bit becomes a fixed-cost bottleneck. Across Transformers, CNNs, and MLPs, learned sign matrices resist low-rank approximation and are spectrally…
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2602.17063ARXIV-DEFAULT
- TL;DR
- Semantic Scholar