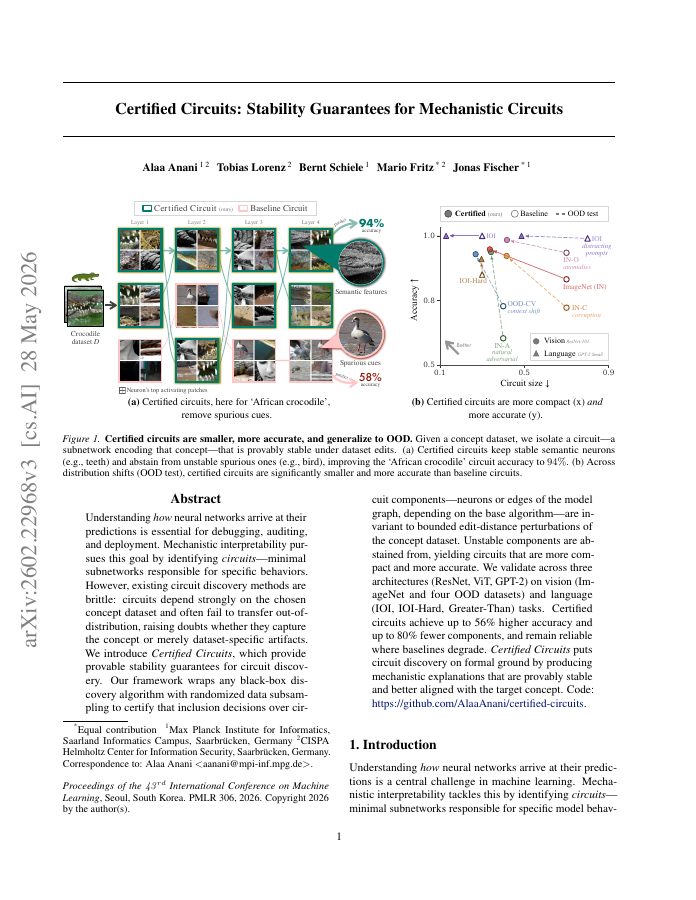
Understanding how neural networks arrive at their predictions is essential for debugging, auditing, and deployment. Mechanistic interpretability pursues this goal by identifying circuits--minimal subnetworks responsible for specific behaviors. However, existing circuit discovery methods are brittle: circuits depend strongly on the chosen concept dataset and often fail to transfer out-of-distribution, raising doubts whether they capture the concept or merely dataset-specific artifacts. We introduce Certified Circuits, which provide provable stability guarantees for circuit discovery. Our framework wraps any black-box discovery algorithm with randomized data subsampling to certify that inclusion decisions over circuit components--neurons or edges of the model graph, depending on the base algorithm--are invariant to bounded edit-distance perturbations of the concept dataset. Unstable components are abstained from, yielding circuits that are more compact and more accurate. We validate across three architectures (ResNet, ViT, GPT-2) on vision (ImageNet and four OOD datasets) and language (IOI, IOI-Hard, Greater-Than) tasks. Certified circuits achieve up to 56% higher accuracy and up to 80% fewer components, and remain reliable where baselines degrade. Certified Circuits puts circuit discovery on formal ground by producing mechanistic explanations that are provably stable and better aligned with the target concept. Code: https://github.com/AlaaAnani/certified-circuits.
Certified Circuits: Stability Guarantees for Mechanistic Circuits
Understanding how neural networks arrive at their predictions is essential for debugging, auditing, and deployment. Mechanistic interpretability pursues this goal by identifying circuits--minimal subnetworks responsible for specific behaviors.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2602.22968CC-BY-4.0
- TL;DR
- Semantic Scholar