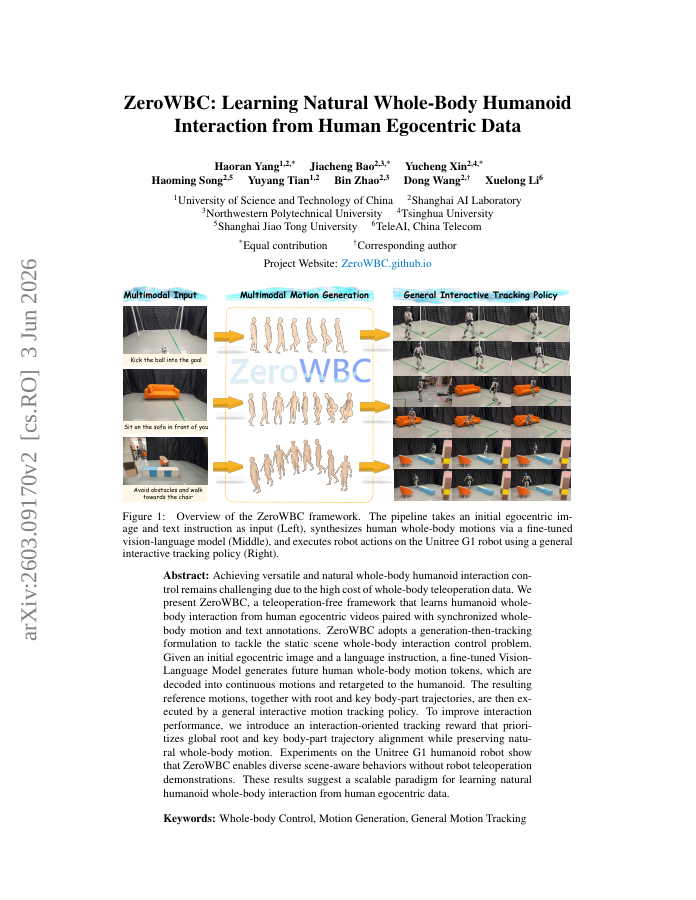
Achieving versatile and natural whole-body humanoid interaction control remains challenging due to the high cost of whole-body teleoperation data. We present ZeroWBC, a teleoperation-free framework that learns humanoid whole-body interaction from human egocentric videos paired with synchronized whole-body motion and text annotations. ZeroWBC adopts a generation-then-tracking formulation to tackle the static scene whole-body interaction control problem. Given an initial egocentric image and a language instruction, a fine-tuned Vision-Language Model generates future human whole-body motion tokens, which are decoded into continuous motions and retargeted to the humanoid. The resulting reference motions, together with root and key body-part trajectories, are then executed by a general interactive motion tracking policy. To improve interaction performance, we introduce an interaction-oriented tracking reward that prioritizes global root and key body-part trajectory alignment while preserving natural whole-body motion. Experiments on the Unitree G1 humanoid robot show that ZeroWBC enables diverse scene-aware behaviors without robot teleoperation demonstrations. These results suggest a scalable paradigm for learning natural humanoid whole-body interaction from human egocentric data.
ZeroWBC: Learning Natural Whole-Body Humanoid Interaction from Human Egocentric Data
Achieving versatile and natural whole-body humanoid interaction control remains challenging due to the high cost of whole-body teleoperation data. We present ZeroWBC, a teleoperation-free framework that learns humanoid whole-body interaction from human egocentric videos paired…
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2603.09170ARXIV-DEFAULT
- TL;DR
- Semantic Scholar