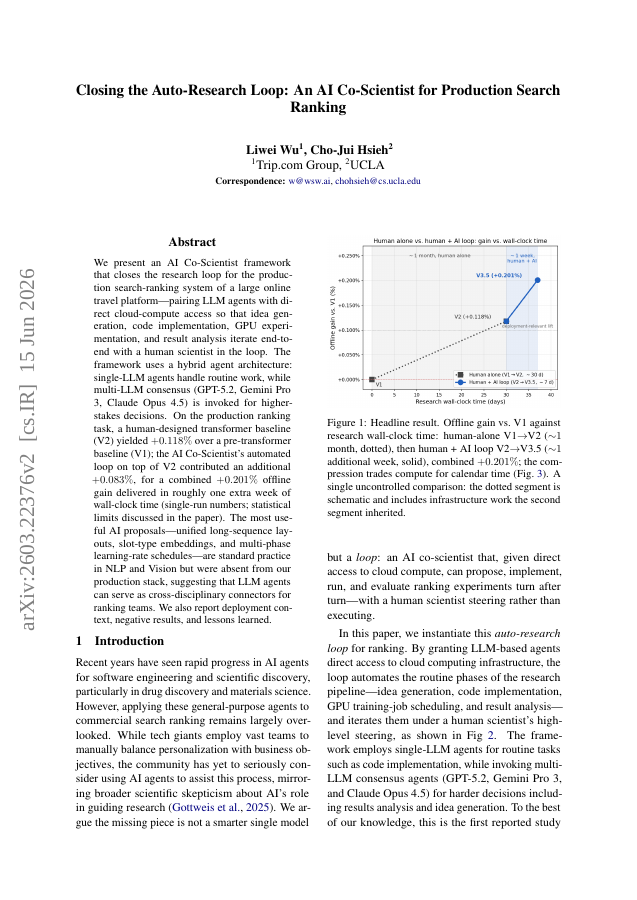
We present an AI Co-Scientist framework that closes the research loop for the production search-ranking system of a large online travel platform -- pairing LLM agents with direct cloud-compute access so that idea generation, code implementation, GPU experimentation, and result analysis iterate end-to-end with a human scientist in the loop. The framework uses a hybrid agent architecture: single-LLM agents handle routine work, while multi-LLM consensus (GPT-5.2, Gemini Pro 3, Claude Opus 4.5) is invoked for higher-stakes decisions. On the production ranking task, a human-designed transformer baseline (V2) yielded +0.118% over a pre-transformer baseline (V1); the AI Co-Scientist's automated loop on top of V2 contributed an additional +0.083%, for a combined +0.201% offline gain delivered in roughly one extra week of wall-clock time (single-run numbers; statistical limits discussed in the paper). The most useful AI proposals -- unified long-sequence layouts, slot-type embeddings, and multi-phase learning-rate schedules -- are standard practice in NLP and Vision but were absent from our production stack, suggesting that LLM agents can serve as cross-disciplinary connectors for ranking teams. We also report deployment context, negative results, and lessons learned.
Closing the Auto-Research Loop: An AI Co-Scientist for Production Search Ranking
We present an AI Co-Scientist framework that closes the research loop for the production search-ranking system of a large online travel platform -- pairing LLM agents with direct cloud-compute access so that idea generation, code implementation, GPU experimentation, and result…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2603.22376CC-BY-4.0
- TL;DR
- Semantic Scholar