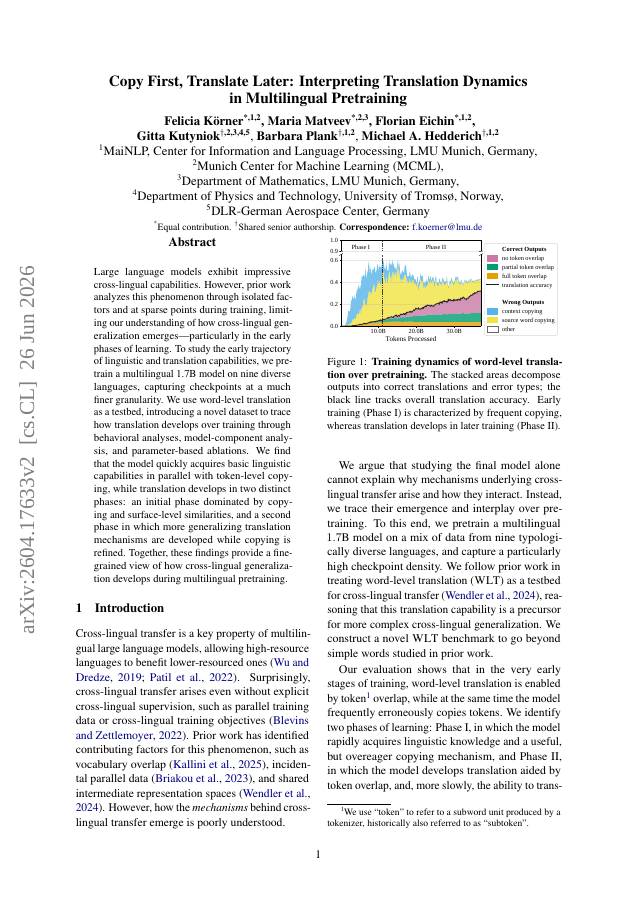
Large language models exhibit impressive cross-lingual capabilities. However, prior work analyzes this phenomenon through isolated factors and at sparse points during training, limiting our understanding of how cross-lingual generalization emerges--particularly in the early phases of learning. To study the early trajectory of linguistic and translation capabilities, we pretrain a multilingual 1.7B model on nine diverse languages, capturing checkpoints at a much finer granularity. We use word-level translation as a testbed, introducing a novel dataset to trace how translation develops over training through behavioral analyses, model-component analysis, and parameter-based ablations. We find that the model quickly acquires basic linguistic capabilities in parallel with token-level copying, while translation develops in two distinct phases: an initial phase dominated by copying and surface-level similarities, and a second phase in which more generalizing translation mechanisms are developed while copying is refined. Together, these findings provide a fine-grained view of how cross-lingual generalization develops during multilingual pretraining.
Copy First, Translate Later: Interpreting Translation Dynamics in Multilingual Pretraining
Large language models exhibit impressive cross-lingual capabilities. However, prior work analyzes this phenomenon through isolated factors and at sparse points during training, limiting our understanding of how cross-lingual generalization emerges--particularly in the early…
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2604.17633ARXIV-DEFAULT
- TL;DR
- Semantic Scholar