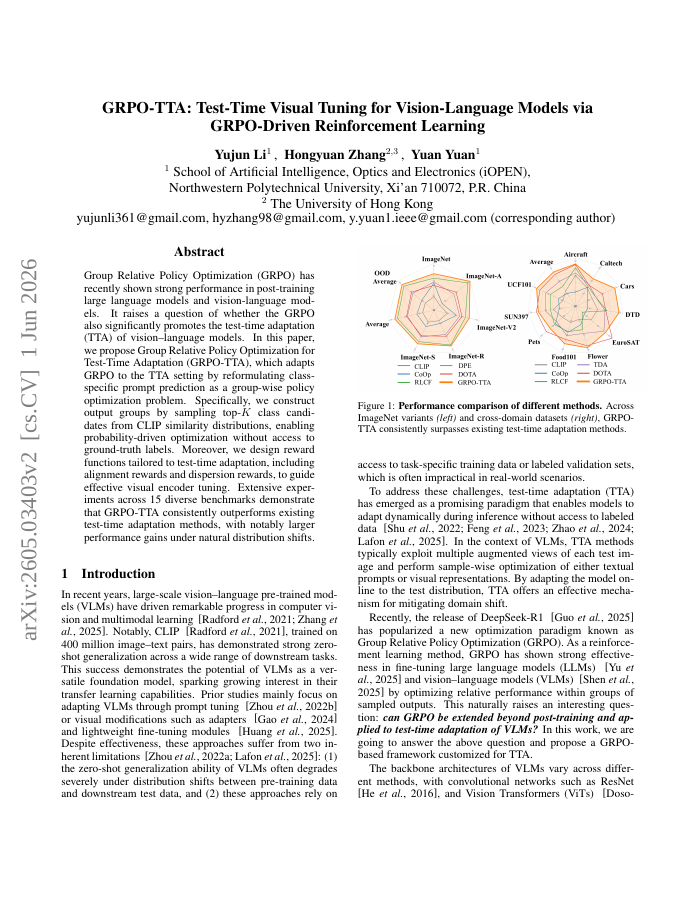
Group Relative Policy Optimization (GRPO) has recently shown strong performance in post-training large language models and vision-language models. It raises a question of whether the GRPO also significantly promotes the test-time adaptation (TTA) of vision language models. In this paper, we propose Group Relative Policy Optimization for Test-Time Adaptation (GRPO-TTA), which adapts GRPO to the TTA setting by reformulating class-specific prompt prediction as a group-wise policy optimization problem. Specifically, we construct output groups by sampling top-K class candidates from CLIP similarity distributions, enabling probability-driven optimization without access to ground-truth labels. Moreover, we design reward functions tailored to test-time adaptation, including alignment rewards and dispersion rewards, to guide effective visual encoder tuning. Extensive experiments across diverse benchmarks demonstrate that GRPO-TTA consistently outperforms existing test-time adaptation methods, with notably larger performance gains under natural distribution shifts.
GRPO-TTA: Test-Time Visual Tuning for Vision-Language Models via GRPO-Driven Reinforcement Learning
Group Relative Policy Optimization (GRPO) has recently shown strong performance in post-training large language models and vision-language models. It raises a question of whether the GRPO also significantly promotes the test-time adaptation (TTA) of vision language models.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2605.03403ARXIV-DEFAULT
- TL;DR
- Semantic Scholar