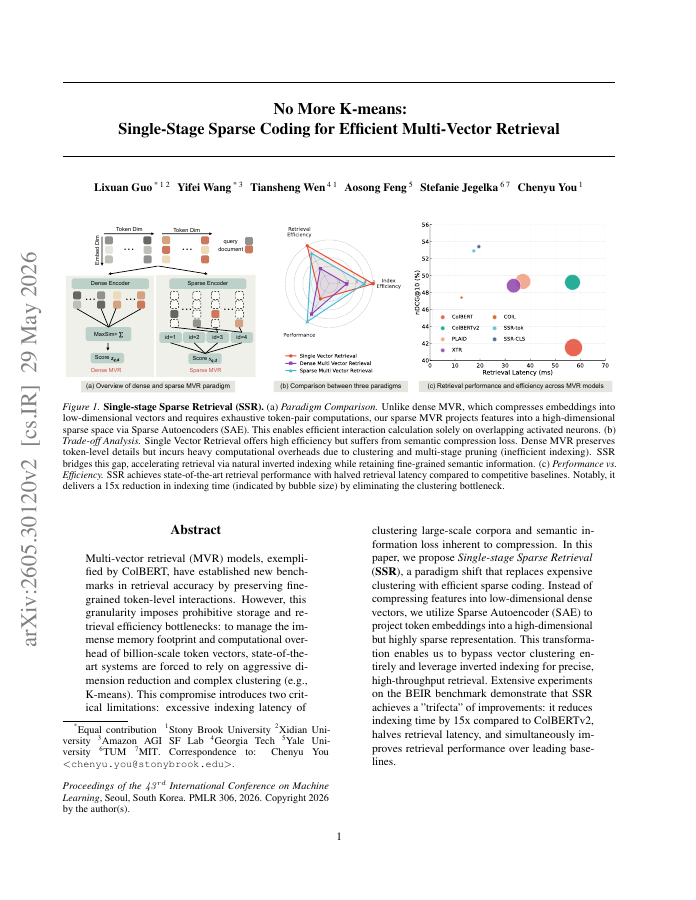
Multi-vector retrieval (MVR) models, exemplified by ColBERT, have established new benchmarks in retrieval accuracy by preserving fine-grained token-level interactions. However, this granularity imposes prohibitive storage and retrieval efficiency bottlenecks: to manage the immense memory footprint and computational overhead of billion-scale token vectors, state-of-the-art systems are forced to rely on aggressive dimension reduction and complex clustering (e.g., K-means). This compromise introduces two critical limitations: excessive indexing latency of clustering large-scale corpora and semantic information loss inherent to compression. In this paper, we propose Single-stage Sparse Retrieval (SSR}, a paradigm shift that replaces expensive clustering with efficient sparse coding. Instead of compressing features into low-dimensional dense vectors, we utilize Sparse Autoencoder (SAE) to project token embeddings into a high-dimensional but highly sparse representation. This transformation enables us to bypass vector clustering entirely and leverage inverted indexing for precise, high-throughput retrieval. Extensive experiments on the BEIR benchmark demonstrate that SSR achieves a "trifecta" of improvements: it reduces indexing time by 15x compared to ColBERTv2, halves retrieval latency, and simultaneously improves retrieval performance over leading baselines.
No More K-means: Single-Stage Sparse Coding for Efficient Multi-Vector Retrieval
Multi-vector retrieval (MVR) models, exemplified by ColBERT, have established new benchmarks in retrieval accuracy by preserving fine-grained token-level interactions. However, this granularity imposes prohibitive storage and retrieval efficiency bottlenecks: to manage the…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2605.30120CC-BY-4.0
- TL;DR
- Semantic Scholar