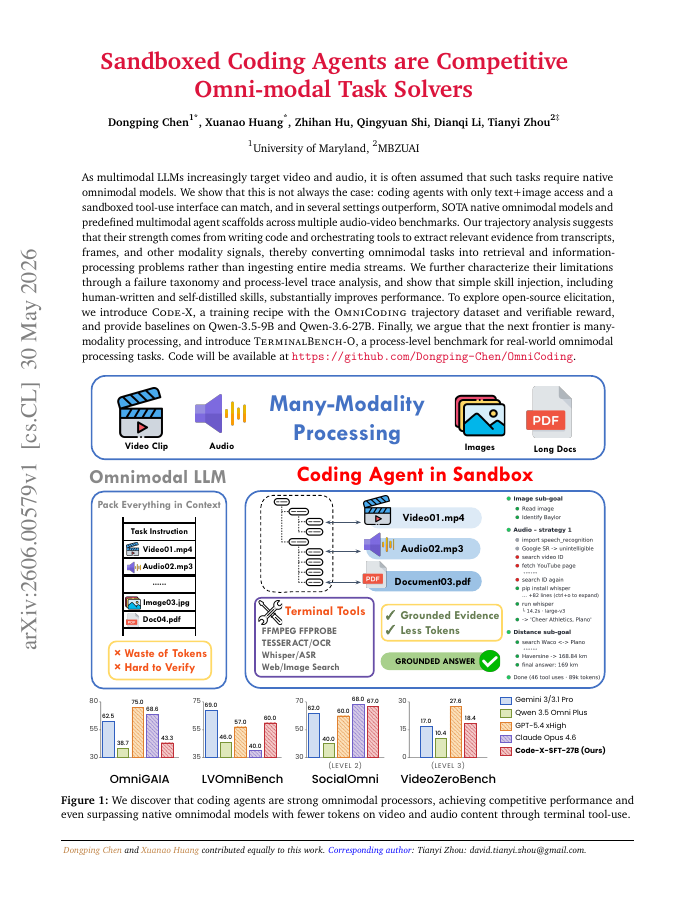
As multimodal LLMs increasingly target video and audio, it is often assumed that such tasks require native omnimodal models. We show that this is not always the case: coding agents with only text+image access and a sandboxed tool-use interface can match, and in several settings outperform, SOTA native omnimodal models and predefined multimodal agent scaffolds across multiple audio-video benchmarks. Our trajectory analysis suggests that their strength comes from writing code and orchestrating tools to extract relevant evidence from transcripts, frames, and other modality signals, thereby converting omnimodal tasks into retrieval and information-processing problems rather than ingesting entire media streams. We further characterize their limitations through a failure taxonomy and process-level trace analysis, and show that simple skill injection, including human-written and self-distilled skills, substantially improves performance. To explore open-source elicitation, we introduce Code-X, a training recipe with the OmniCoding trajectory dataset and verifiable reward, and provide baselines on Qwen-3.5-9B and Qwen-3.6-27B. Finally, we argue that the next frontier is many-modality processing, and introduce TerminalBench-O, a process-level benchmark for real-world omnimodal processing tasks. Code will be available at https://github.com/Dongping-Chen/OmniCoding.
Sandboxed Coding Agents are Competitive Omni-modal Task Solvers
As multimodal LLMs increasingly target video and audio, it is often assumed that such tasks require native omnimodal models. We show that this is not always the case: coding agents with only text+image access and a sandboxed tool-use interface can match, and in several settings…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.00579CC-BY-4.0
- TL;DR
- Semantic Scholar