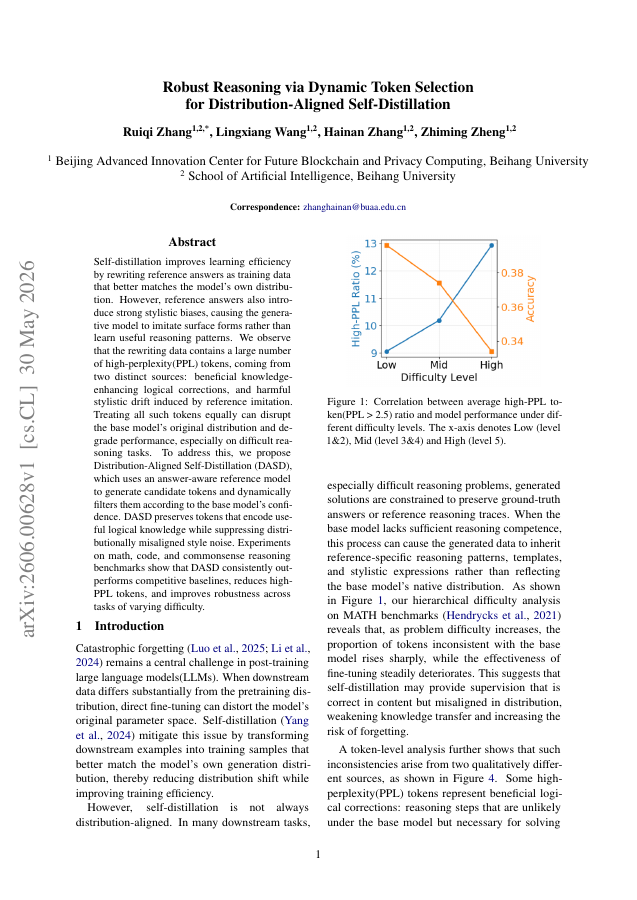
Self-distillation improves learning efficiency by rewriting reference answers as training data that better matches the model's own distribution. However, reference answers also introduce strong stylistic biases, causing the generative model to imitate surface forms rather than learn useful reasoning patterns. We observe that the rewriting data contains a large number of high-perplexity (PPL) tokens, coming from two distinct sources: beneficial knowledge-enhancing logical corrections, and harmful stylistic drift induced by reference imitation. Treating all such tokens equally can disrupt the base model's original distribution and degrade performance, especially on difficult reasoning tasks. To address this, we propose Distribution-Aligned Self-Distillation (DASD), which uses an answer-aware reference model to generate candidate tokens and dynamically filters them according to the base model's confidence. DASD preserves tokens that encode useful logical knowledge while suppressing distributionally misaligned style noise. Experiments on math, code, and commonsense reasoning benchmarks show that DASD consistently outperforms competitive baselines, reduces high-PPL tokens, and improves robustness across tasks of varying difficulty.
Robust Reasoning via Dynamic Token Selection for Distribution-Aligned Self-Distillation
Self-distillation improves learning efficiency by rewriting reference answers as training data that better matches the model's own distribution. However, reference answers also introduce strong stylistic biases, causing the generative model to imitate surface forms rather than…
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.00628ARXIV-DEFAULT
- TL;DR
- Semantic Scholar