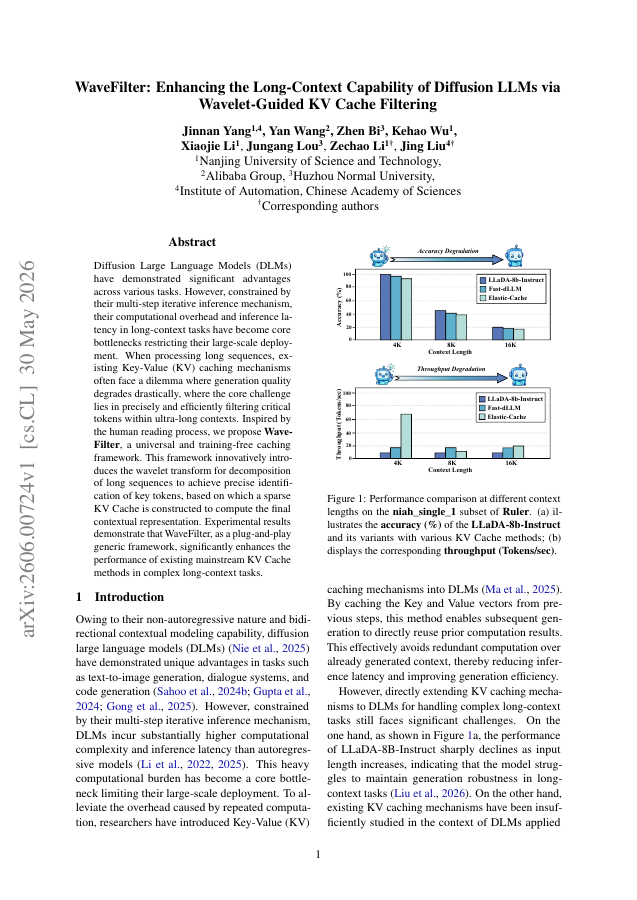
Diffusion Large Language Models (DLMs) have demonstrated significant advantages across various tasks. However, constrained by their multi-step iterative inference mechanism, their computational overhead and inference latency in long-context tasks have become core bottlenecks restricting their large-scale deployment. When processing long sequences, existing Key-Value (KV) caching mechanisms often face a dilemma where generation quality degrades drastically, where the core challenge lies in precisely and efficiently filtering critical tokens within ultra-long contexts. Inspired by the human reading process, we propose \textbf{WaveFilter}, a universal and training-free caching framework. This framework innovatively introduces the wavelet transform for decomposition of long sequences to achieve precise identification of key tokens, based on which a sparse KV Cache is constructed to compute the final contextual representation. Experimental results demonstrate that WaveFilter, as a plug-and-play generic framework, significantly enhances the performance of existing mainstream KV Cache methods in complex long-context tasks.
WaveFilter: Enhancing the Long-Context Capability of Diffusion LLMs via Wavelet-Guided KV Cache Filtering
Diffusion Large Language Models (DLMs) have demonstrated significant advantages across various tasks. However, constrained by their multi-step iterative inference mechanism, their computational overhead and inference latency in long-context tasks have become core bottlenecks…
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.00724ARXIV-DEFAULT
- TL;DR
- Semantic Scholar