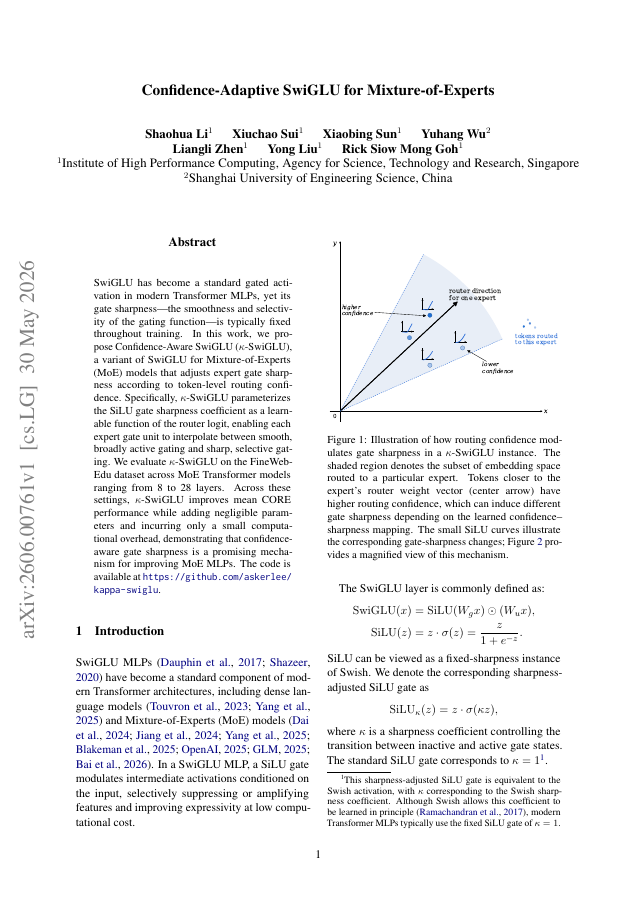
SwiGLU has become a standard gated activation in modern Transformer MLPs, yet its gate sharpness -- the smoothness and selectivity of the gating function -- is typically fixed throughout training. In this work, we propose Confidence-Aware SwiGLU ($κ$-SwiGLU), a variant of SwiGLU for Mixture-of-Experts (MoE) models that adjusts expert gate sharpness according to token-level routing confidence. Specifically, $κ$-SwiGLU parameterizes the SiLU gate sharpness coefficient as a learnable function of the router logit, enabling each expert gate unit to interpolate between smooth, broadly active gating and sharp, selective gating. We evaluate $κ$-SwiGLU on the FineWeb-Edu dataset across MoE Transformer models ranging from 8 to 28 layers. Across these settings, $κ$-SwiGLU improves mean CORE performance while adding negligible parameters and incurring only a small computational overhead, demonstrating that confidence-aware gate sharpness is a promising mechanism for improving MoE MLPs. The code is available at https://github.com/askerlee/kappa-swiglu.
Confidence-Adaptive SwiGLU for Mixture-of-Experts
SwiGLU has become a standard gated activation in modern Transformer MLPs, yet its gate sharpness -- the smoothness and selectivity of the gating function -- is typically fixed throughout training.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.00761ARXIV-DEFAULT
- TL;DR
- Semantic Scholar