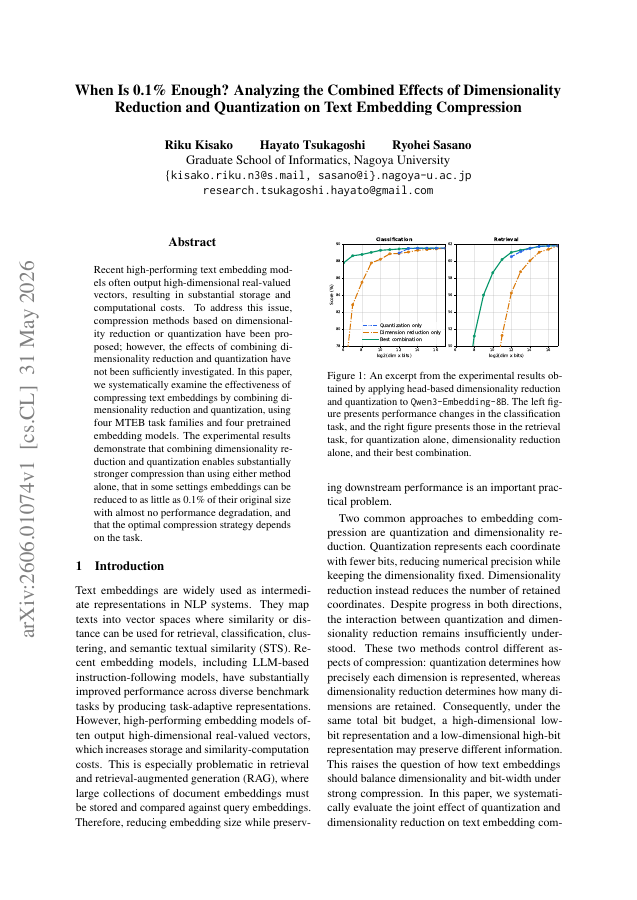
Recent high-performing text embedding models often output high-dimensional real-valued vectors, resulting in substantial storage and computational costs. To address this issue, compression methods based on dimensionality reduction or quantization have been proposed; however, the effects of combining dimensionality reduction and quantization have not been sufficiently investigated. In this paper, we systematically examine the effectiveness of compressing text embeddings by combining dimensionality reduction and quantization, using four MTEB task families and four pretrained embedding models. The experimental results demonstrate that combining dimensionality reduction and quantization enables substantially stronger compression than using either method alone, that in some settings embeddings can be reduced to as little as 0.1% of their original size with almost no performance degradation, and that the optimal compression strategy depends on the task.
When Is 0.1% Enough? Analyzing the Combined Effects of Dimensionality Reduction and Quantization on Text Embedding Compression
Recent high-performing text embedding models often output high-dimensional real-valued vectors, resulting in substantial storage and computational costs. To address this issue, compression methods based on dimensionality reduction or quantization have been proposed; however, the…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.01074CC-BY-4.0
- TL;DR
- Semantic Scholar