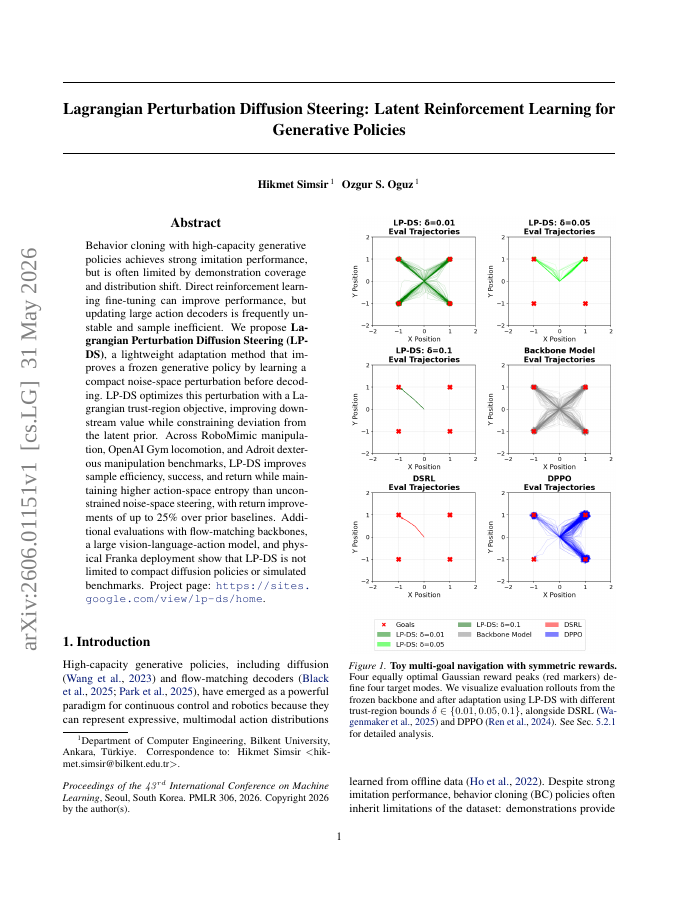
Behavior cloning with high-capacity generative policies achieves strong imitation performance, but is often limited by demonstration coverage and distribution shift. Direct reinforcement learning fine-tuning can improve performance, but updating large action decoders is frequently unstable and sample inefficient. We propose Lagrangian Perturbation Diffusion Steering (LP-DS), a lightweight adaptation method that improves a frozen generative policy by learning a compact noise-space perturbation before decoding. LP-DS optimizes this perturbation with a Lagrangian trust-region objective, improving downstream value while constraining deviation from the latent prior. Across RoboMimic manipulation, OpenAI Gym locomotion, and Adroit dexterous manipulation benchmarks, LP-DS improves sample efficiency, success, and return while maintaining higher action-space entropy than unconstrained noise-space steering, with return improvements of up to 25% over prior baselines. Additional evaluations with flow-matching backbones, a large vision-language-action model, and physical Franka deployment show that LP-DS is not limited to compact diffusion policies or simulated benchmarks. Project page: https://sites.google.com/view/lp-ds/home.
Lagrangian Perturbation Diffusion Steering: Latent Reinforcement Learning for Generative Policies
Behavior cloning with high-capacity generative policies achieves strong imitation performance, but is often limited by demonstration coverage and distribution shift. Direct reinforcement learning fine-tuning can improve performance, but updating large action decoders is…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.01151CC-BY-4.0
- TL;DR
- Semantic Scholar