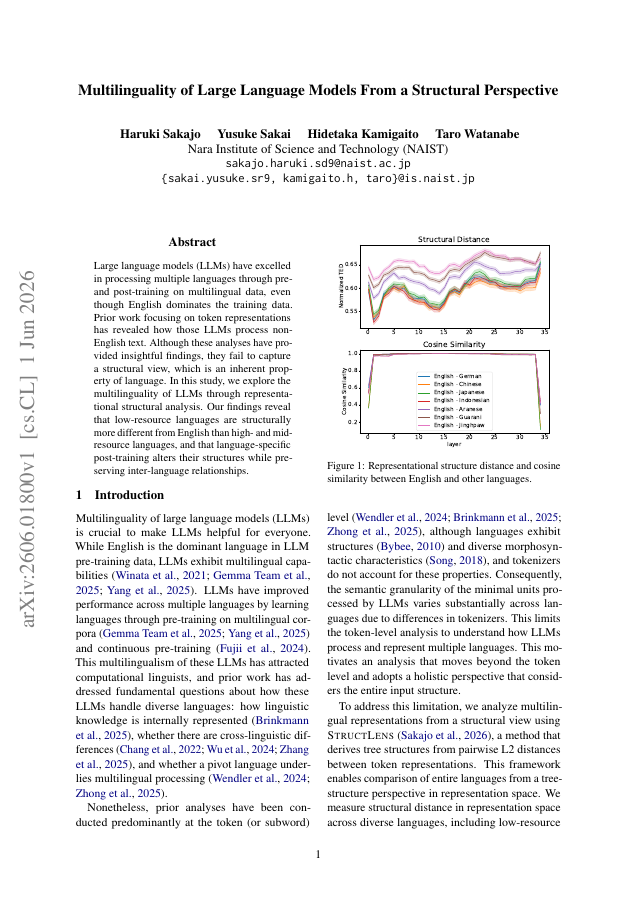
Large language models (LLMs) have excelled in processing multiple languages through pre- and post-training on multilingual data, even though English dominates the training data. Prior work focusing on token representations has revealed how those LLMs process non-English text. Although these analyses have provided insightful findings, they fail to capture a structural view, which is an inherent property of language. In this study, we explore the multilinguality of LLMs through representational structural analysis. Our findings reveal that low-resource languages are structurally more different from English than high- and mid-resource languages, and that language-specific post-training alters their structures while preserving inter-language relationships.
Multilinguality of Large Language Models From a Structural Perspective
Large language models (LLMs) have excelled in processing multiple languages through pre- and post-training on multilingual data, even though English dominates the training data. Prior work focusing on token representations has revealed how those LLMs process non-English text.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.01800CC-BY-4.0
- TL;DR
- Semantic Scholar