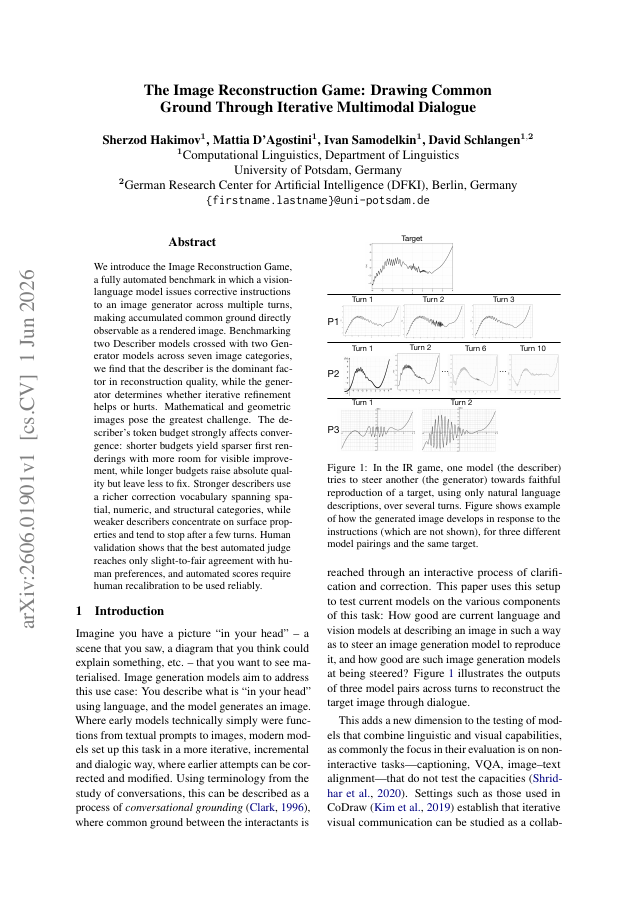
We introduce the Image Reconstruction Game, a fully automated benchmark in which a vision-language model issues corrective instructions to an image generator across multiple turns, making accumulated common ground directly observable as a rendered image. Benchmarking two Describer models crossed with two Generator models across seven image categories, we find that the describer is the dominant factor in reconstruction quality, while the generator determines whether iterative refinement helps or hurts. Mathematical and geometric images pose the greatest challenge. The describer's token budget strongly affects convergence: shorter budgets yield sparser first renderings with more room for visible improvement, while longer budgets raise absolute quality but leave less to fix. Stronger describers use a richer correction vocabulary spanning spatial, numeric, and structural categories, while weaker describers concentrate on surface properties and tend to stop after a few turns. Human validation shows that the best automated judge reaches only slight-to-fair agreement with human preferences, and automated scores require human recalibration to be used reliably.
The Image Reconstruction Game: Drawing Common Ground Through Iterative Multimodal Dialogue
We introduce the Image Reconstruction Game, a fully automated benchmark in which a vision-language model issues corrective instructions to an image generator across multiple turns, making accumulated common ground directly observable as a rendered image.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-SA-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.01901CC-BY-SA-4.0
- TL;DR
- Semantic Scholar