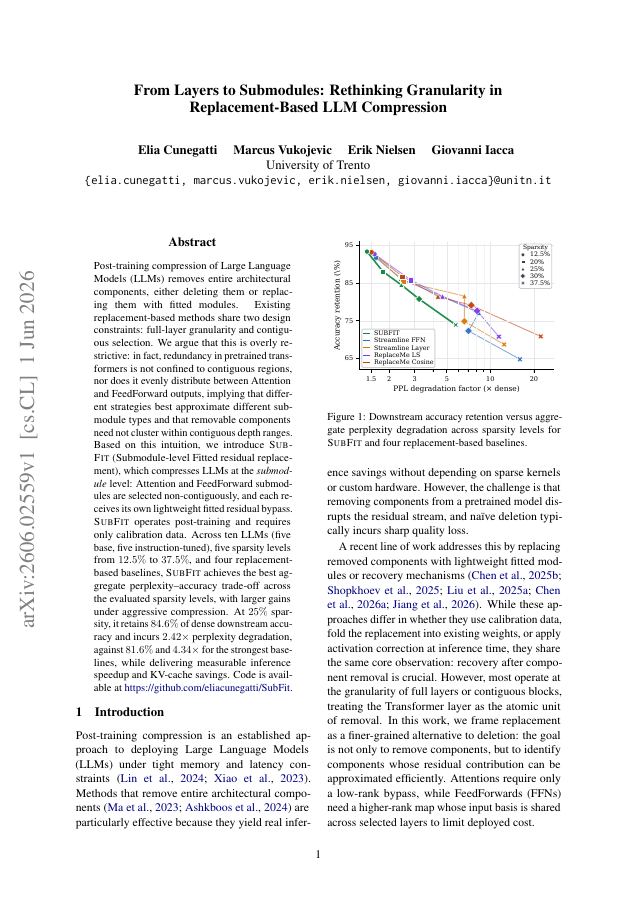
Post-training compression of Large Language Models (LLMs) removes entire architectural components, either deleting them or replacing them with fitted modules. Existing replacement-based methods share two design constraints: full-layer granularity and contiguous selection. We argue that this is overly restrictive: in fact, redundancy in pretrained transformers is not confined to contiguous regions, nor does it evenly distribute between Attention and FeedForward outputs, implying that different strategies best approximate different submodule types and that removable components need not cluster within contiguous depth ranges. Based on this intuition, we introduce SubFit (Submodule-level Fitted residual replacement), which compresses LLMs at the submodule level: Attention and FeedForward submodules are selected non-contiguously, and each receives its own lightweight fitted residual bypass. SubFit operates post-training and requires only calibration data. Across ten LLMs (five base, five instruction-tuned), five sparsity levels from 12.5% to 37.5%, and four replacement-based baselines, SubFit achieves the best aggregate perplexity-accuracy trade-off across the evaluated sparsity levels, with larger gains under aggressive compression. At 25% sparsity, it retains 84.6% of dense downstream accuracy and incurs 2.42x perplexity degradation, against 81.6% and 4.34x for the strongest baselines, while delivering measurable inference speedup and KV-cache savings. Code is available at https://github.com/eliacunegatti/SubFit.
From Layers to Submodules: Rethinking Granularity in Replacement-Based LLM Compression
Post-training compression of Large Language Models (LLMs) removes entire architectural components, either deleting them or replacing them with fitted modules. Existing replacement-based methods share two design constraints: full-layer granularity and contiguous selection.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.02559CC-BY-4.0
- TL;DR
- Semantic Scholar