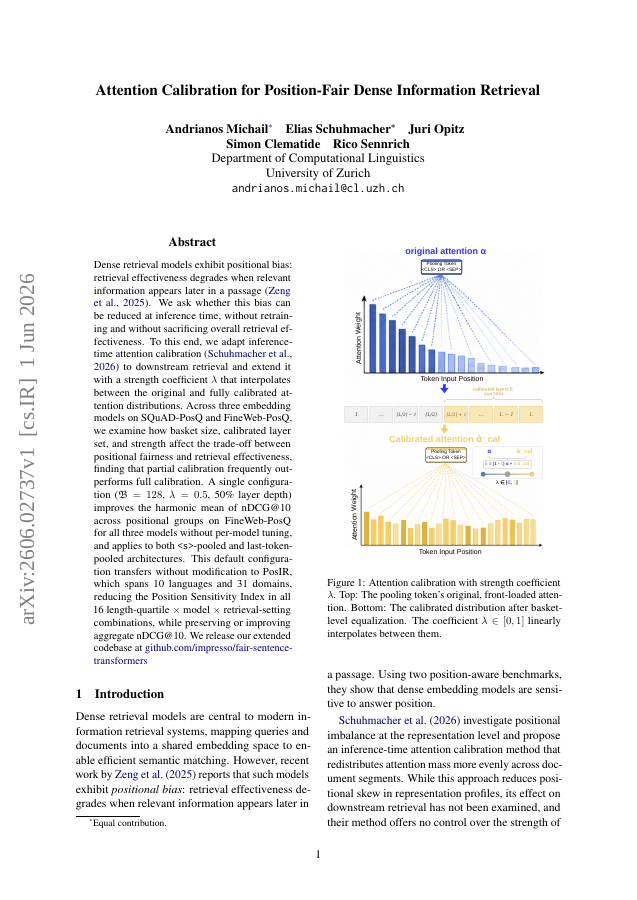
Dense retrieval models exhibit positional bias: retrieval effectiveness degrades when relevant information appears later in a passage (Zeng et al., 2025). We ask whether this bias can be reduced at inference time, without retraining and without sacrificing overall retrieval effectiveness. To this end, we adapt inference-time attention calibration (Schuhmacher et al., 2026) to downstream retrieval and extend it with a strength coefficient lambda that interpolates between the original and fully calibrated attention distributions. Across three embedding models on SQuAD-PosQ and FineWeb-PosQ, we examine how basket size, calibrated layer set, and strength affect the trade-off between positional fairness and retrieval effectiveness, finding that partial calibration frequently outperforms full calibration. A single configuration (B=128, lambda=0.5, 50% layer depth) improves the harmonic mean of nDCG@10 across positional groups on FineWeb-PosQ for all three models without per-model tuning, and applies to both -pooled and last-token-pooled architectures. This default configuration transfers without modification to PosIR, which spans 10 languages and 31 domains, reducing the Position Sensitivity Index in all 16 length-quartile x model x retrieval-setting combinations, while preserving or improving aggregate nDCG@10. We release our extended codebase at https://github.com/impresso/fair-sentence-transformers
Attention Calibration for Position-Fair Dense Information Retrieval
Dense retrieval models exhibit positional bias: retrieval effectiveness degrades when relevant information appears later in a passage (Zeng et al., 2025). We ask whether this bias can be reduced at inference time, without retraining and without sacrificing overall retrieval…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.02737CC-BY-4.0
- TL;DR
- Semantic Scholar