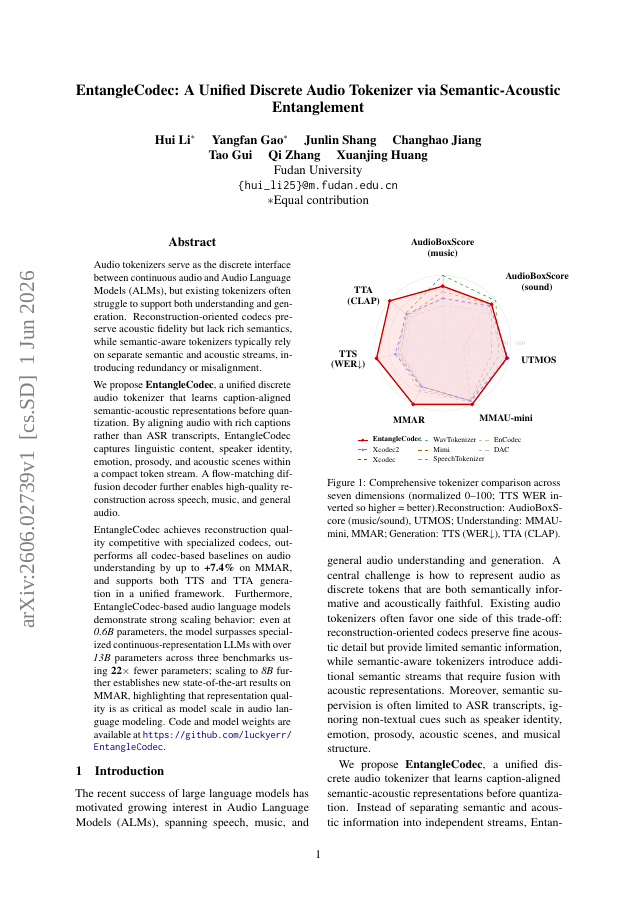
Audio tokenizers serve as the discrete interface between continuous audio and Audio Language Models (ALMs), but existing tokenizers often struggle to support both understanding and generation. Reconstruction-oriented codecs preserve acoustic fidelity but lack rich semantics, while semantic-aware tokenizers typically rely on separate semantic and acoustic streams, introducing redundancy or misalignment. We propose EntangleCodec, a unified discrete audio tokenizer that learns caption-aligned semantic-acoustic representations before quantization. By aligning audio with rich captions rather than ASR transcripts, EntangleCodec captures linguistic content, speaker identity, emotion, prosody, and acoustic scenes within a compact token stream. A flow-matching diffusion decoder further enables high-quality reconstruction across speech, music, and general audio. EntangleCodec achieves reconstruction quality competitive with specialized codecs, outperforms all codec-based baselines on audio understanding by up to +7.4% on MMAR, and supports both TTS and TTA generation in a unified framework. Furthermore, EntangleCodec-based audio language models demonstrate strong scaling behavior: even at 0.6B parameters, the model surpasses specialized continuous-representation LLMs with over 13B parameters across three benchmarks using 22\times fewer parameters; scaling to 8B further establishes new state-of-the-art results on MMAR, highlighting that representation quality is as critical as model scale in audio language modeling. Code and model weights are available at https://github.com/luckyerr/EntangleCodec.
EntangleCodec: A Unified Discrete Audio Tokenizer via Semantic-Acoustic Entanglement
Audio tokenizers serve as the discrete interface between continuous audio and Audio Language Models (ALMs), but existing tokenizers often struggle to support both understanding and generation.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.02739CC-BY-4.0
- TL;DR
- Semantic Scholar