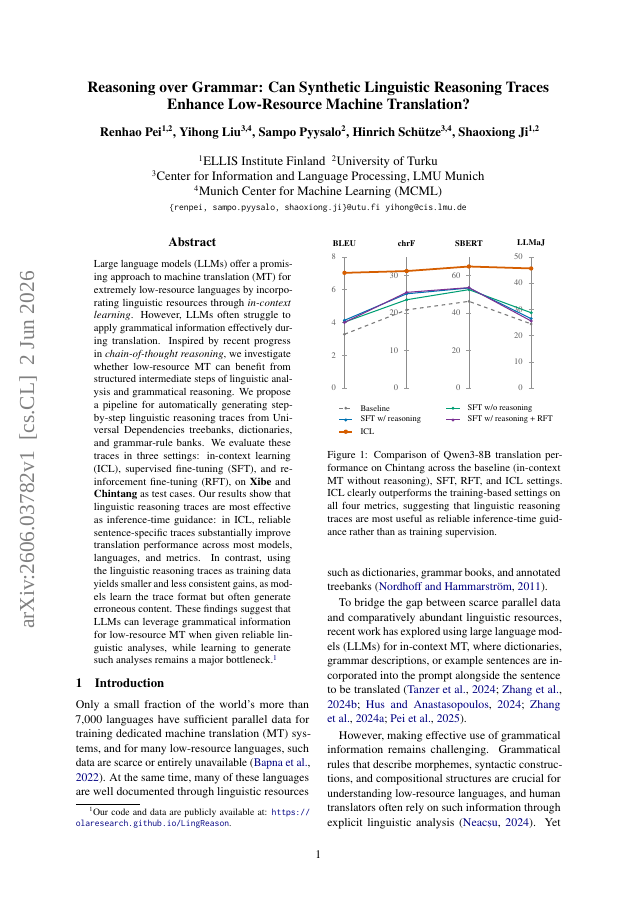
Large language models (LLMs) offer a promising approach to machine translation (MT) for extremely low-resource languages by incorporating linguistic resources through in-context learning. However, LLMs often struggle to apply grammatical information effectively during translation. Inspired by recent progress in chain-of-thought reasoning, we investigate whether low-resource MT can benefit from structured intermediate steps of linguistic analysis and grammatical reasoning. We propose a pipeline for automatically generating step-by-step linguistic reasoning traces from Universal Dependencies treebanks, dictionaries, and grammar-rule banks. We evaluate these traces in three settings: in-context learning (ICL), supervised fine-tuning (SFT), and reinforcement fine-tuning (RFT), on Xibe and Chintang as test cases. Our results show that linguistic reasoning traces are most effective as inference-time guidance: in ICL, reliable sentence-specific traces substantially improve translation performance across most models, languages, and metrics. In contrast, using the linguistic reasoning traces as training data yields smaller and less consistent gains, as models learn the trace format but often generate erroneous content. These findings suggest that LLMs can leverage grammatical information for low-resource MT when given reliable linguistic analyses, while learning to generate such analyses remains a major bottleneck.
Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
Large language models (LLMs) offer a promising approach to machine translation (MT) for extremely low-resource languages by incorporating linguistic resources through in-context learning.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.03782ARXIV-DEFAULT
- TL;DR
- Semantic Scholar