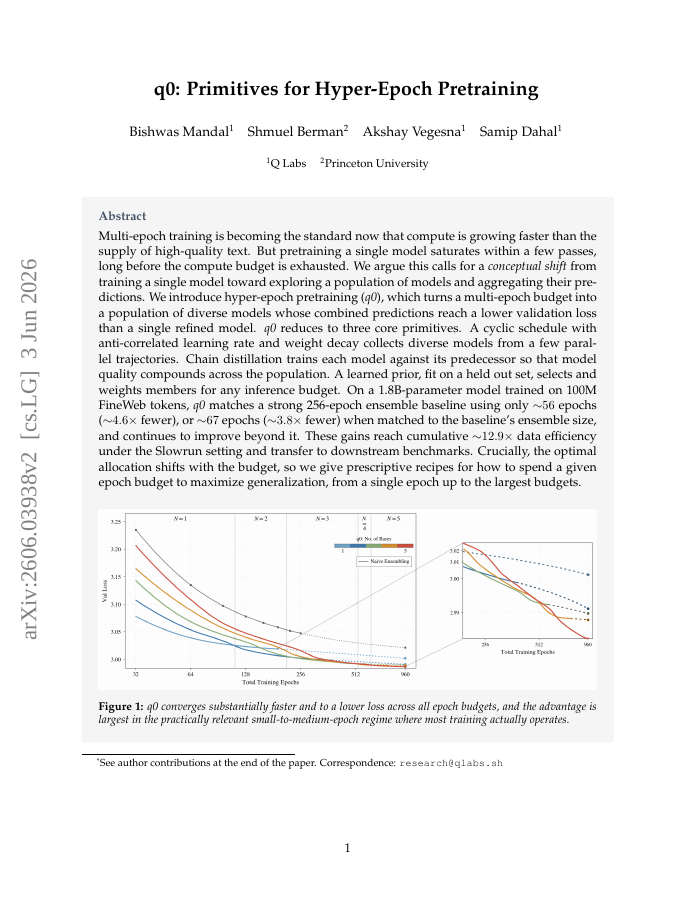
Multi-epoch training is becoming the standard now that compute is growing faster than the supply of high-quality text. But pretraining a single model saturates within a few passes, long before the compute budget is exhausted. We argue this calls for a conceptual shift from training a single model toward exploring a population of models and aggregating their predictions. We introduce hyper-epoch pretraining (q0), which turns a multi-epoch budget into a population of diverse models whose combined predictions reach a lower validation loss than a single refined model. q0 reduces to three core primitives. A cyclic schedule with anti-correlated learning rate and weight decay collects diverse models from a few parallel trajectories. Chain distillation trains each model against its predecessor so that model quality compounds across the population. A learned prior, fit on a held out set, selects and weights members for any inference budget. On a 1.8B-parameter model trained on 100M FineWeb tokens, q0 matches a strong 256-epoch ensemble baseline using only 56 epochs ( 4.6x fewer), or 67 epochs ( 3.8x fewer) when matched to the baseline's ensemble size, and continues to improve beyond it. These gains reach cumulative 12.9x data efficiency under the Slowrun setting and transfer to downstream benchmarks. Crucially, the optimal allocation shifts with the budget, so we give prescriptive recipes for how to spend a given epoch budget to maximize generalization, from a single epoch up to the largest budgets.
q0: Primitives for Hyper-Epoch Pretraining
Multi-epoch training is becoming the standard now that compute is growing faster than the supply of high-quality text. But pretraining a single model saturates within a few passes, long before the compute budget is exhausted.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.03938CC-BY-4.0
- TL;DR
- Semantic Scholar