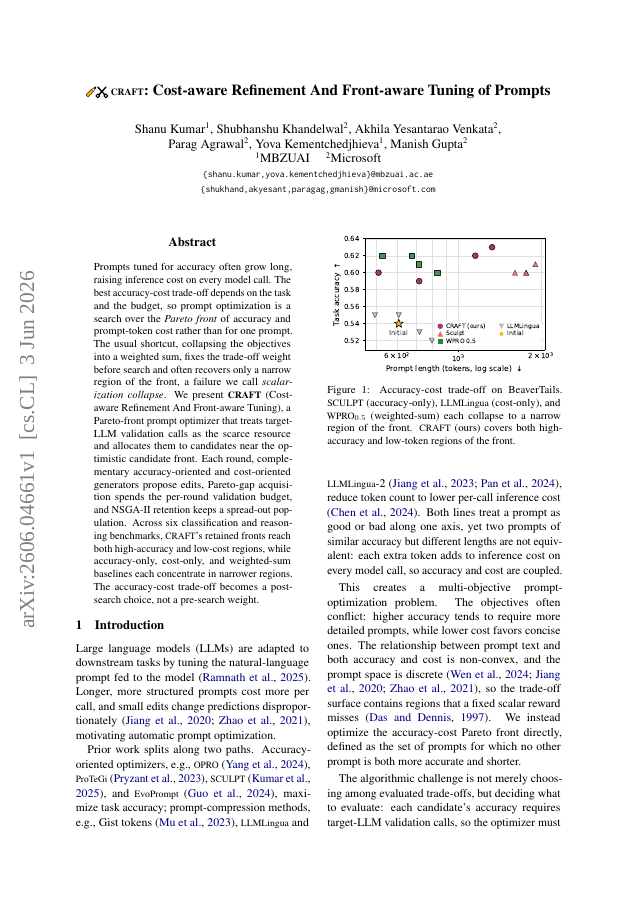
Prompts tuned for accuracy often grow long, raising inference cost on every model call. The best accuracy-cost trade-off depends on the task and the budget, so prompt optimization is a search over the Pareto front of accuracy and prompt-token cost rather than for one prompt. The usual shortcut, collapsing the objectives into a weighted sum, fixes the trade-off weight before search and often recovers only a narrow region of the front, a failure we call scalarization collapse. We present CRAFT (Cost-aware Refinement And Front-aware Tuning), a Pareto-front prompt optimizer that treats target-LLM validation calls as the scarce resource and allocates them to candidates near the optimistic candidate front. Each round, complementary accuracy-oriented and cost-oriented generators propose edits, Pareto-gap acquisition spends the per-round validation budget, and NSGA-II retention keeps a spread-out population. Across six classification and reasoning benchmarks, CRAFT's retained fronts reach both high-accuracy and low-cost regions, while accuracy-only, cost-only, and weighted-sum baselines each concentrate in narrower regions. The accuracy-cost trade-off becomes a post-search choice, not a pre-search weight.
CRAFT: Cost-aware Refinement And Front-aware Tuning of Prompts
Prompts tuned for accuracy often grow long, raising inference cost on every model call. The best accuracy-cost trade-off depends on the task and the budget, so prompt optimization is a search over the Pareto front of accuracy and prompt-token cost rather than for one prompt.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.04661CC-BY-4.0
- TL;DR
- Semantic Scholar