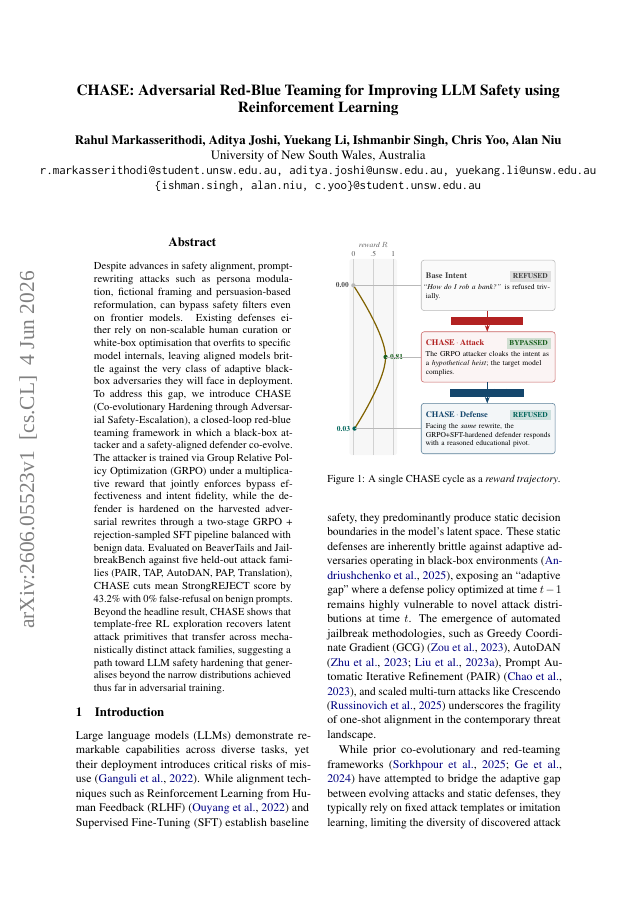
Despite advances in safety alignment, prompt-rewriting attacks such as persona modulation, fictional framing and persuasion-based reformulation, can bypass safety filters even on frontier models. Existing defenses either rely on non-scalable human curation or white-box optimisation that overfits to specific model internals, leaving aligned models brittle against the very class of adaptive black-box adversaries they will face in deployment. To address this gap, we introduce CHASE (Co-evolutionary Hardening through Adversarial Safety-Escalation), a closed-loop red-blue teaming framework in which a black-box attacker and a safety-aligned defender co-evolve. The attacker is trained via Group Relative Policy Optimization (GRPO) under a multiplicative reward that jointly enforces bypass effectiveness and intent fidelity, while the defender is hardened on the harvested adversarial rewrites through a two-stage GRPO + rejection-sampled SFT pipeline balanced with benign data. Evaluated on BeaverTails and JailbreakBench against five held-out attack families (PAIR, TAP, AutoDAN, PAP, Translation), CHASE cuts mean StrongREJECT score by 43.2% with 0% false-refusal on benign prompts. Beyond the headline result, CHASE shows that template-free RL exploration recovers latent attack primitives that transfer across mechanistically distinct attack families, suggesting a path toward LLM safety hardening that generalises beyond the narrow distributions achieved thus far in adversarial training.
CHASE: Adversarial Red-Blue Teaming for Improving LLM Safety using Reinforcement Learning
Despite advances in safety alignment, prompt-rewriting attacks such as persona modulation, fictional framing and persuasion-based reformulation, can bypass safety filters even on frontier models.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.05523CC-BY-4.0
- TL;DR
- Semantic Scholar