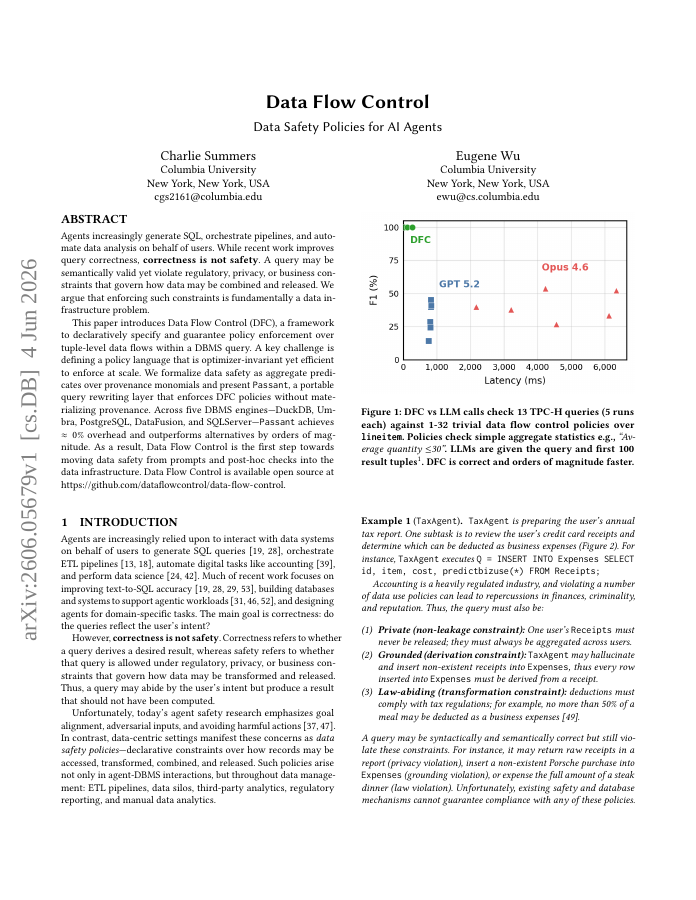
Agents increasingly generate SQL, orchestrate pipelines, and automate data analysis on behalf of users. While recent work improves query correctness, correctness is not safety. A query may be semantically valid yet violate regulatory, privacy, or business constraints that govern how data may be combined and released. We argue that enforcing such constraints is fundamentally a data infrastructure problem. This paper introduces Data Flow Control (DFC), a framework to declaratively specify and guarantee policy enforcement over tuple-level data flows within a DBMS query. A key challenge is defining a policy language that is optimizer-invariant yet efficient to enforce at scale. We formalize data safety as aggregate predicates over provenance monomials and present Passant, a portable query rewriting layer that enforces DFC policies without materializing provenance. Across five DBMS engines -- DuckDB, Umbra, PostgreSQL, DataFusion, and SQLServer -- Passant achieves 0% overhead and outperforms alternatives by orders of magnitude. As a result, Data Flow Control is the first step towards moving data safety from prompts and post-hoc checks into the data infrastructure. Data Flow Control is available open source at https://github.com/dataflowcontrol/data-flow-control.
Data Flow Control: Data Safety Policies for AI Agents
Agents increasingly generate SQL, orchestrate pipelines, and automate data analysis on behalf of users. While recent work improves query correctness, correctness is not safety.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.05679CC-BY-4.0
- TL;DR
- Semantic Scholar