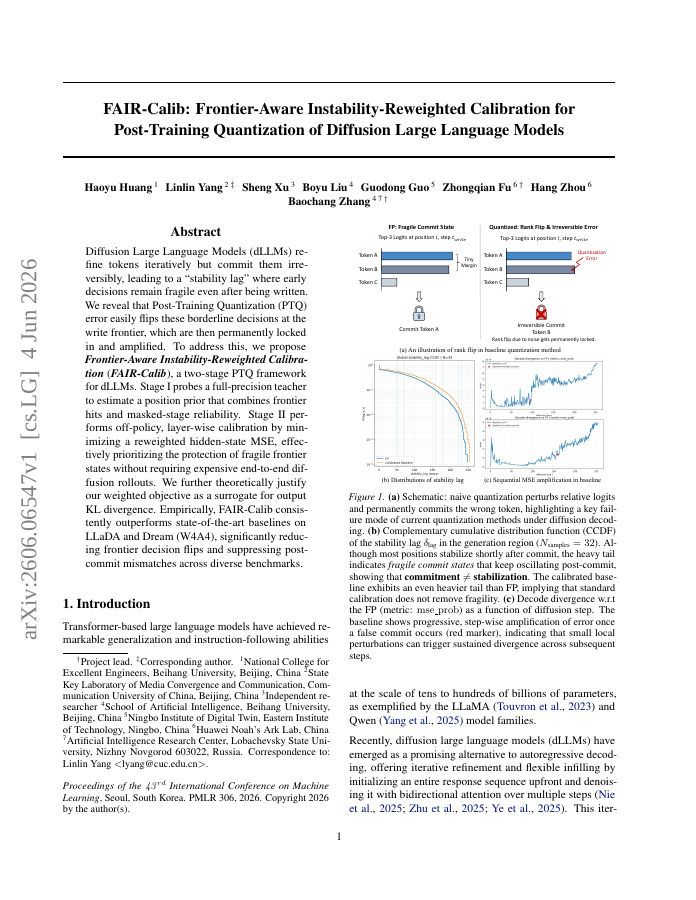
Diffusion Large Language Models (dLLMs) refine tokens iteratively but commit them irreversibly, leading to a "stability lag" where early decisions remain fragile even after being written. We reveal that Post-Training Quantization (PTQ) error easily flips these borderline decisions at the write frontier, which are then permanently locked in and amplified. To address this, we propose Frontier-Aware Instability-Reweighted Calibration (FAIR-Calib), a two-stage PTQ framework for dLLMs. Stage I probes a full-precision teacher to estimate a position prior that combines frontier hits and masked-stage reliability. Stage II performs off-policy, layer-wise calibration by minimizing a reweighted hidden-state MSE, effectively prioritizing the protection of fragile frontier states without requiring expensive end-to-end diffusion rollouts. We further theoretically justify our weighted objective as a surrogate for output KL divergence. Empirically, FAIR-Calib consistently outperforms state-of-the-art baselines on LLaDA and Dream (W4A4), significantly reducing frontier decision flips and suppressing post-commit mismatches across diverse benchmarks.
FAIR-Calib: Frontier-Aware Instability-Reweighted Calibration for Post-Training Quantization of Diffusion Large Language Models
Diffusion Large Language Models (dLLMs) refine tokens iteratively but commit them irreversibly, leading to a "stability lag" where early decisions remain fragile even after being written.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.06547CC-BY-4.0
- TL;DR
- Semantic Scholar