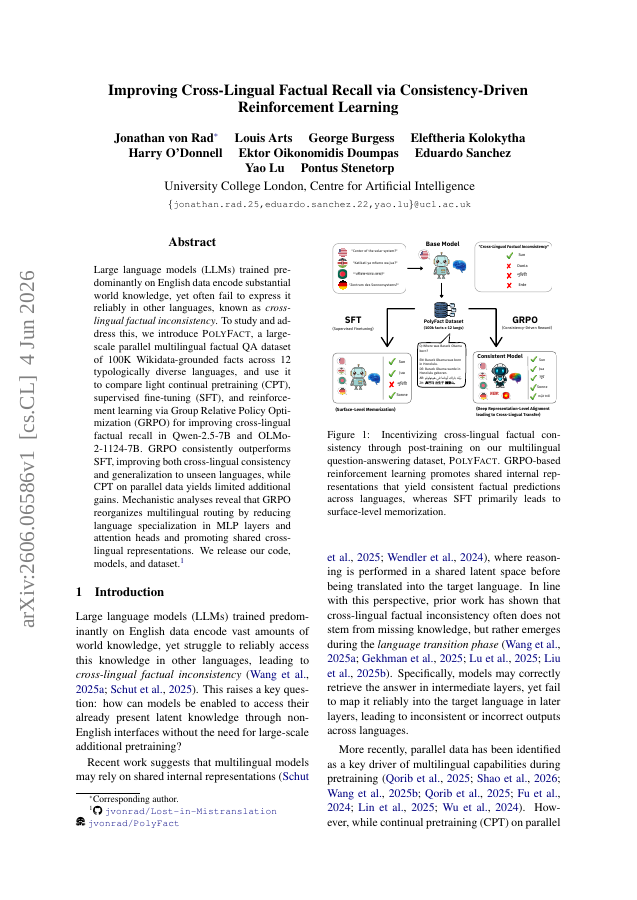
Large language models (LLMs) trained predominantly on English data encode substantial world knowledge, yet often fail to express it reliably in other languages, a phenomenon known as cross-lingual factual inconsistency. To study and address this, we introduce PolyFact, a large-scale parallel multilingual factual QA dataset containing 100K Wikidata-grounded facts across 12 typologically diverse languages. Using PolyFact, we compare light continual pretraining (CPT), supervised fine-tuning (SFT), and reinforcement learning via Group Relative Policy Optimization (GRPO) for improving cross-lingual factual recall in Qwen-2.5-7B and OLMo-2-1124-7B. We find that GRPO consistently outperforms SFT, improving both cross-lingual consistency and generalization to unseen languages, while CPT on parallel data yields limited additional gains. Mechanistic analyses further show that GRPO reorganizes multilingual routing by reducing language specialization in MLP layers and attention heads, thereby promoting more shared cross-lingual representations. We release our code, models, and dataset.
Improving Cross-Lingual Factual Recall via Consistency-Driven Reinforcement Learning
Large language models (LLMs) trained predominantly on English data encode substantial world knowledge, yet often fail to express it reliably in other languages, a phenomenon known as cross-lingual factual inconsistency.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.06586CC-BY-4.0
- TL;DR
- Semantic Scholar