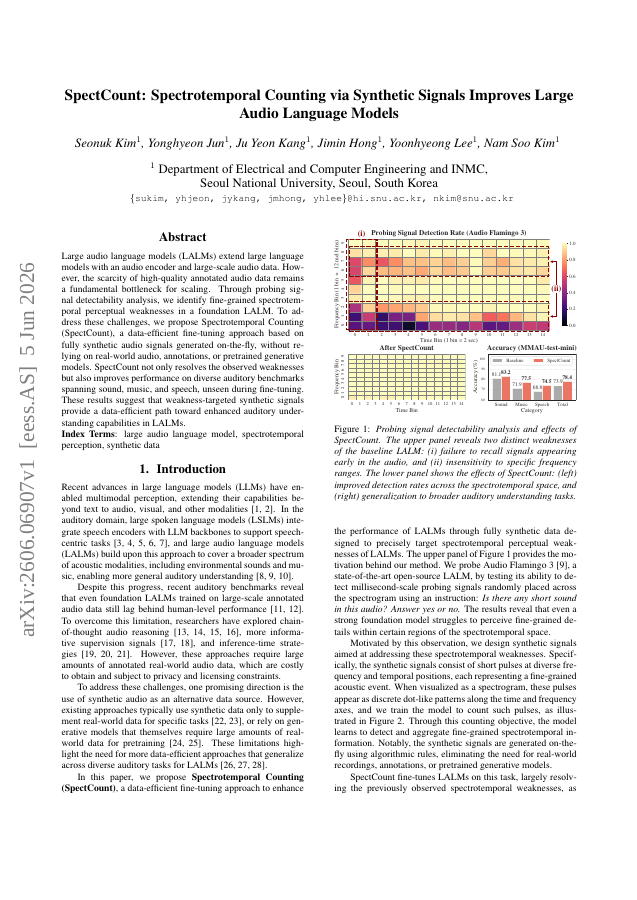
Large audio language models (LALMs) extend large language models with an audio encoder and large-scale audio data. However, the scarcity of high-quality annotated audio data remains a fundamental bottleneck for scaling. Through probing signal detectability analysis, we identify fine-grained spectrotemporal perceptual weaknesses in a foundation LALM. To address these challenges, we propose Spectrotemporal Counting (SpectCount), a data-efficient fine-tuning approach based on fully synthetic audio signals generated on-the-fly, without relying on real-world audio, annotations, or pretrained generative models. SpectCount not only resolves the observed weaknesses but also improves performance on diverse auditory benchmarks spanning sound, music, and speech, unseen during fine-tuning. These results suggest that weakness-targeted synthetic signals provide a data-efficient path toward enhanced auditory understanding capabilities in LALMs.
SpectCount: Spectrotemporal Counting via Synthetic Signals Improves Large Audio Language Models
Large audio language models (LALMs) extend large language models with an audio encoder and large-scale audio data. However, the scarcity of high-quality annotated audio data remains a fundamental bottleneck for scaling.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.06907ARXIV-DEFAULT
- TL;DR
- Semantic Scholar