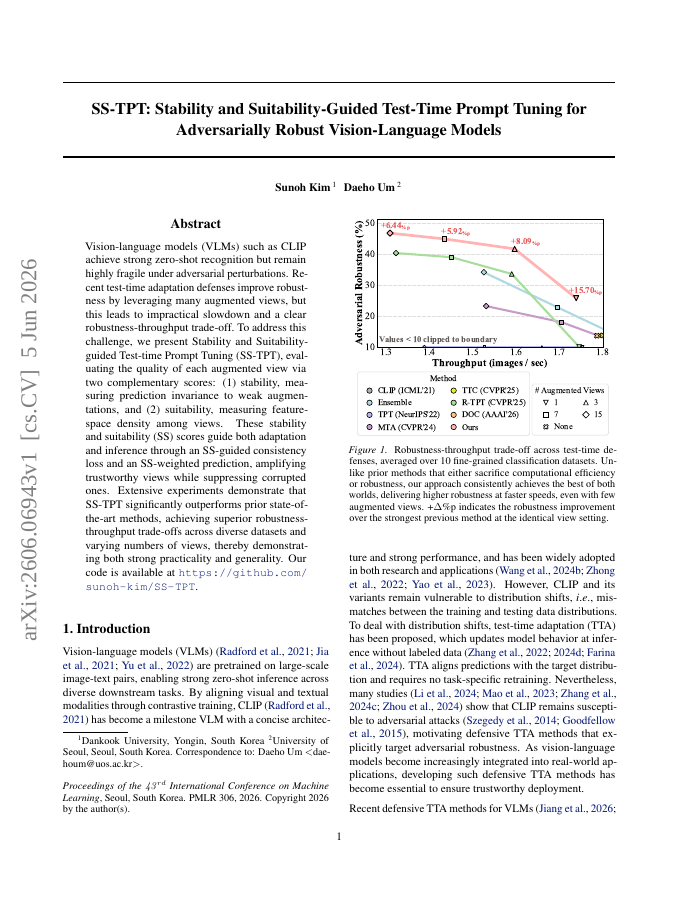
Vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition but remain highly fragile under adversarial perturbations. Recent test-time adaptation defenses improve robustness by leveraging many augmented views, but this leads to impractical slowdown and a clear robustness-throughput trade-off. To address this challenge, we present Stability and Suitability-guided Test-time Prompt Tuning (SS-TPT), evaluating the quality of each augmented view via two complementary scores: (1) stability, measuring prediction invariance to weak augmentations, and (2) suitability, measuring feature-space density among views. These stability and suitability (SS) scores guide both adaptation and inference through an SS-guided consistency loss and an SS-weighted prediction, amplifying trustworthy views while suppressing corrupted ones. Extensive experiments demonstrate that SS-TPT significantly outperforms prior state-of-the-art methods, achieving superior robustness-throughput trade-offs across diverse datasets and varying numbers of views, thereby demonstrating both strong practicality and generality. Our code is available at https://github.com/sunoh-kim/SS-TPT.
SS-TPT: Stability and Suitability-Guided Test-Time Prompt Tuning for Adversarially Robust Vision-Language Models
Vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition but remain highly fragile under adversarial perturbations. Recent test-time adaptation defenses improve robustness by leveraging many augmented views, but this leads to impractical slowdown and a…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.06943CC-BY-4.0
- TL;DR
- Semantic Scholar