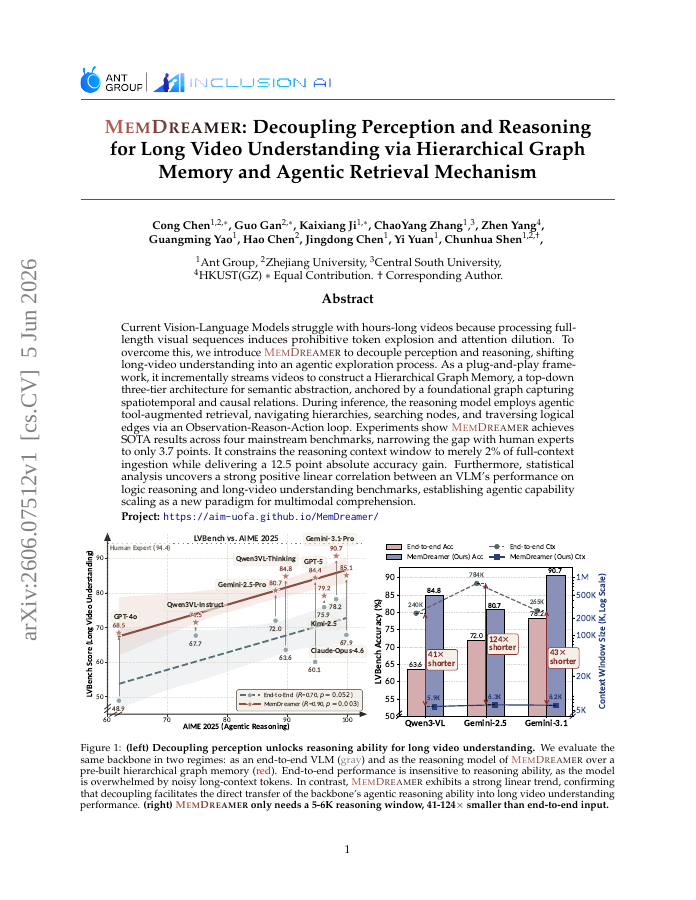
Current Vision-Language Models struggle with hours-long videos because processing full-length visual sequences induces prohibitive token explosion and attention dilution. To overcome this, we introduce MemDreamer to decouple perception and reasoning, shifting long-video understanding into an agentic exploration process. As a plug-and-play framework, it incrementally streams videos to construct a Hierarchical Graph Memory, a top-down three-tier architecture for semantic abstraction, anchored by a foundational graph capturing spatiotemporal and causal relations. During inference, the reasoning model employs agentic tool-augmented retrieval, navigating hierarchies, searching nodes, and traversing logical edges via an Observation-Reason-Action loop. Experiments show MemDreamer achieves SOTA results across four mainstream benchmarks, narrowing the gap with human experts to only 3.7 points. It constrains the reasoning context window to merely 2% of full-context ingestion while delivering a 12.5 point absolute accuracy gain. Furthermore, statistical analysis uncovers a strong positive linear correlation between an VLM's performance on logic reasoning and long-video understanding benchmarks, establishing agentic capability scaling as a new paradigm for multimodal comprehension.
MemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism
Current Vision-Language Models struggle with hours-long videos because processing full-length visual sequences induces prohibitive token explosion and attention dilution.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.07512CC-BY-4.0
- TL;DR
- Semantic Scholar