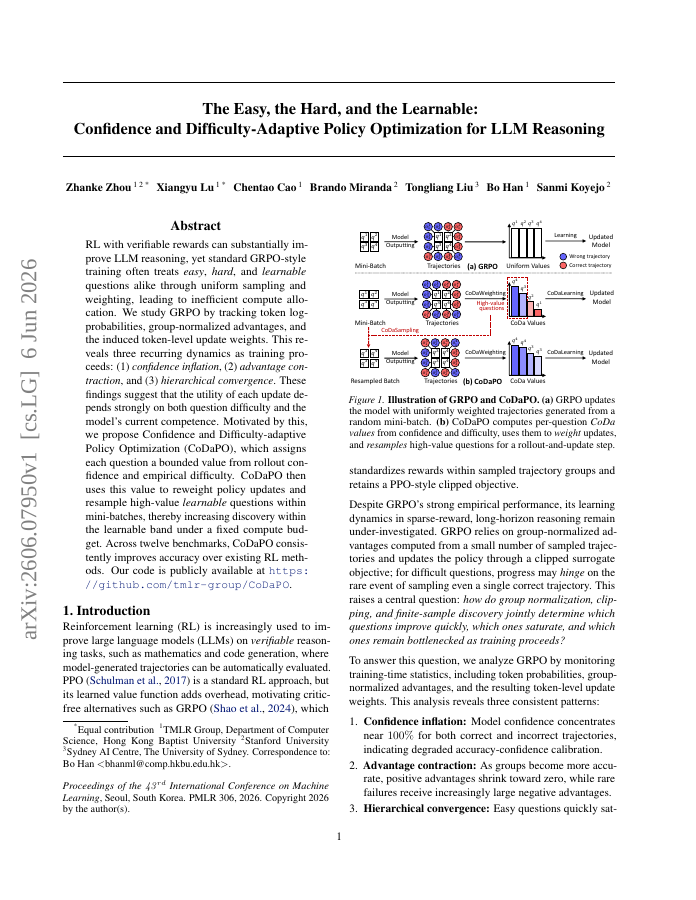
RL with verifiable rewards can substantially improve LLM reasoning, yet standard GRPO-style training often treats easy, hard, and learnable questions alike through uniform sampling and weighting, leading to inefficient compute allocation. We study GRPO by tracking token log-probabilities, group-normalized advantages, and the induced token-level update weights. This reveals three recurring dynamics as training proceeds: (1) confidence inflation, (2) advantage contraction, and (3) hierarchical convergence. These findings suggest that the utility of each update depends strongly on both question difficulty and the model's current competence. Motivated by this, we propose Confidence and Difficulty-adaptive Policy Optimization (CoDaPO), which assigns each question a bounded value from rollout confidence and empirical difficulty. CoDaPO then uses this value to reweight policy updates and resample high-value learnable questions within mini-batches, thereby increasing discovery within the learnable band under a fixed compute budget. Across twelve benchmarks, CoDaPO consistently improves accuracy over existing RL methods. Our code is publicly available at https://github.com/tmlr-group/CoDaPO.
The Easy, the Hard, and the Learnable: Confidence and Difficulty-Adaptive Policy Optimization for LLM Reasoning
RL with verifiable rewards can substantially improve LLM reasoning, yet standard GRPO-style training often treats easy, hard, and learnable questions alike through uniform sampling and weighting, leading to inefficient compute allocation.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.07950ARXIV-DEFAULT
- TL;DR
- Semantic Scholar