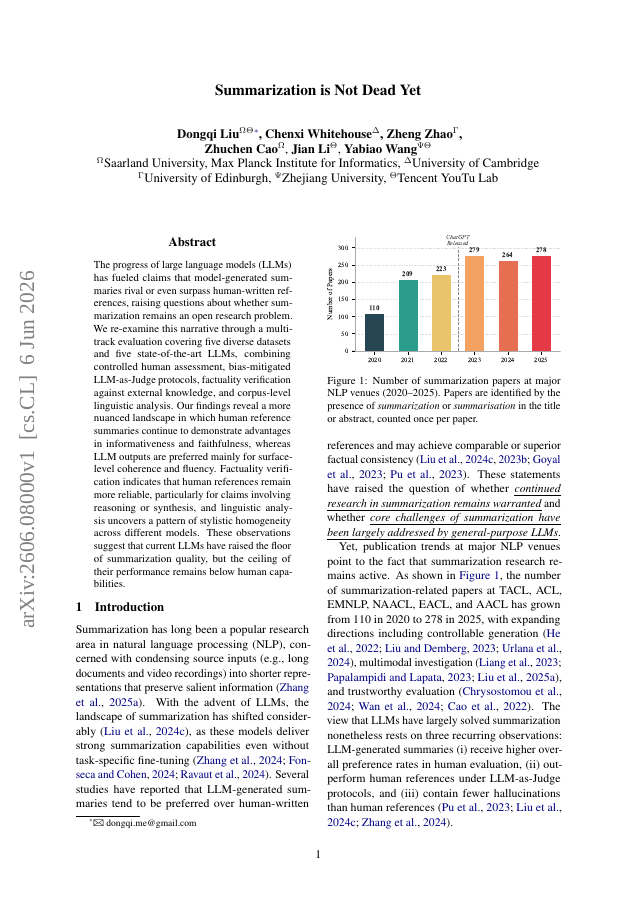
The progress of large language models (LLMs) has fueled claims that model-generated summaries rival or even surpass human-written references, raising questions about whether summarization remains an open research problem. We re-examine this narrative through a multi-track evaluation covering five diverse datasets and five state-of-the-art LLMs, combining controlled human assessment, bias-mitigated LLM-as-Judge protocols, factuality verification against external knowledge, and corpus-level linguistic analysis. Our findings reveal a more nuanced landscape in which human reference summaries continue to demonstrate advantages in informativeness and faithfulness, whereas LLM outputs are preferred mainly for surface-level coherence and fluency. Factuality verification indicates that human references remain more reliable, particularly for claims involving reasoning or synthesis, and linguistic analysis uncovers a pattern of stylistic homogeneity across different models. These observations suggest that current LLMs have raised the floor of summarization quality, but the ceiling of their performance remains below human capabilities.
Summarization is Not Dead Yet
The progress of large language models (LLMs) has fueled claims that model-generated summaries rival or even surpass human-written references, raising questions about whether summarization remains an open research problem.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.08000CC-BY-4.0
- TL;DR
- Semantic Scholar