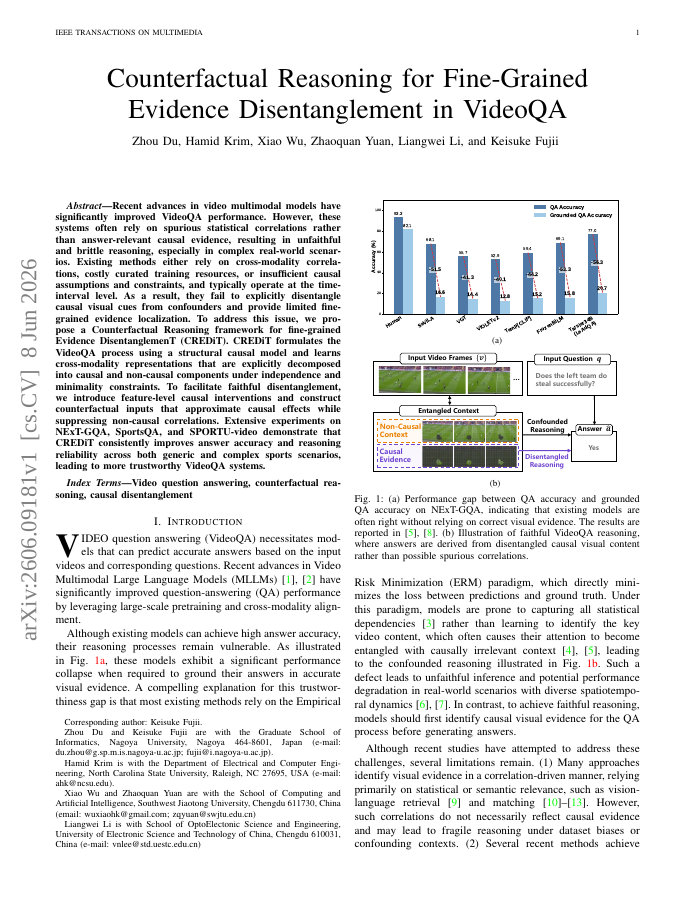
Recent advances in video multimodal models have significantly improved VideoQA performance. However, these systems often rely on spurious statistical correlations rather than answer-relevant causal evidence, resulting in unfaithful and brittle reasoning, especially in complex real-world scenarios. Existing methods either rely on cross-modality correlations, costly curated training resources, or insufficient causal assumptions and constraints, and typically operate at the time-interval level. As a result, they fail to explicitly disentangle causal visual cues from confounders and provide limited fine-grained evidence localization. To address this issue, we propose a Counterfactual Reasoning framework for fine-grained Evidence Disentanglement (CREDiT). CREDiT formulates the VideoQA process using a structural causal model and learns cross-modality representations that are explicitly decomposed into causal and non-causal components under independence and minimality constraints. To facilitate faithful disentanglement, we introduce feature-level causal interventions and construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations. Extensive experiments on NExT-GQA, SportsQA, and SPORTU-video demonstrate that CREDiT consistently improves answer accuracy and reasoning reliability across both generic and complex sports scenarios, leading to more trustworthy VideoQA systems.
Counterfactual Reasoning for Fine-Grained Evidence Disentanglement in VideoQA
Recent advances in video multimodal models have significantly improved VideoQA performance. However, these systems often rely on spurious statistical correlations rather than answer-relevant causal evidence, resulting in unfaithful and brittle reasoning, especially in complex…
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.09181ARXIV-DEFAULT
- TL;DR
- Semantic Scholar