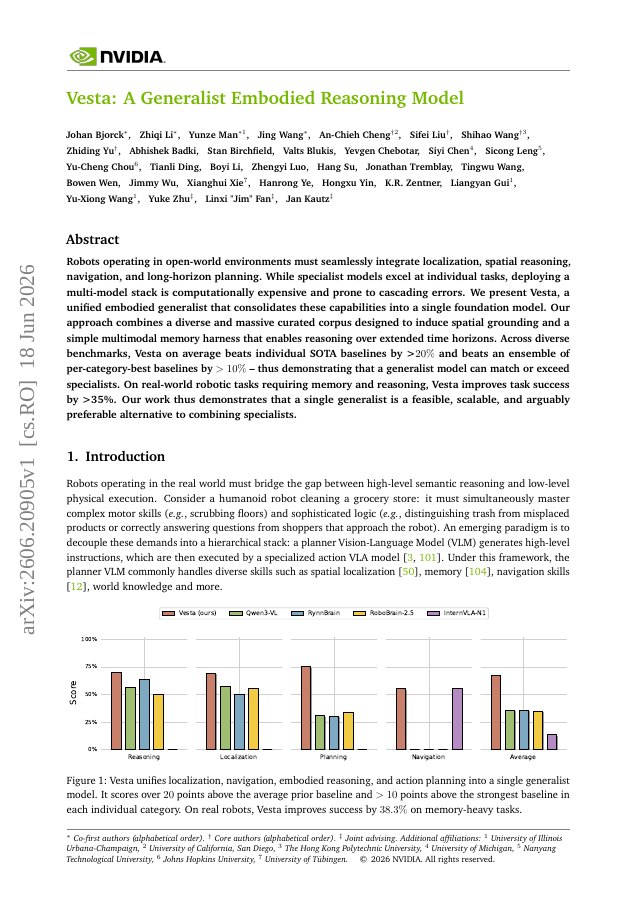
Robots operating in open-world environments must seamlessly integrate localization, spatial reasoning, navigation, and long-horizon planning. While specialist models excel at individual tasks, deploying a multi-model stack is computationally expensive and prone to cascading errors. We present Vesta, a unified embodied generalist that consolidates these capabilities into a single foundation model. Our approach combines a diverse and massive curated corpus designed to induce spatial grounding and a simple multimodal memory harness that enables reasoning over extended time horizons. Across diverse benchmarks, Vesta on average beats individual SOTA baselines by >20% and beats an ensemble of per-category-best baselines by >10% -- thus demonstrating that a generalist model can match or exceed specialists. On real-world robotic tasks requiring memory and reasoning, Vesta improves task success by >35%. Our work thus demonstrates that a single generalist is a feasible, scalable, and arguably preferable alternative to combining specialists.
Vesta: A Generalist Embodied Reasoning Model
Robots operating in open-world environments must seamlessly integrate localization, spatial reasoning, navigation, and long-horizon planning. While specialist models excel at individual tasks, deploying a multi-model stack is computationally expensive and prone to cascading…
- Preview
- Year
- 2026
- Hosting
- Excerpt onlyCC-BY-NC-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.20905CC-BY-NC-4.0
- TL;DR
- Semantic Scholar