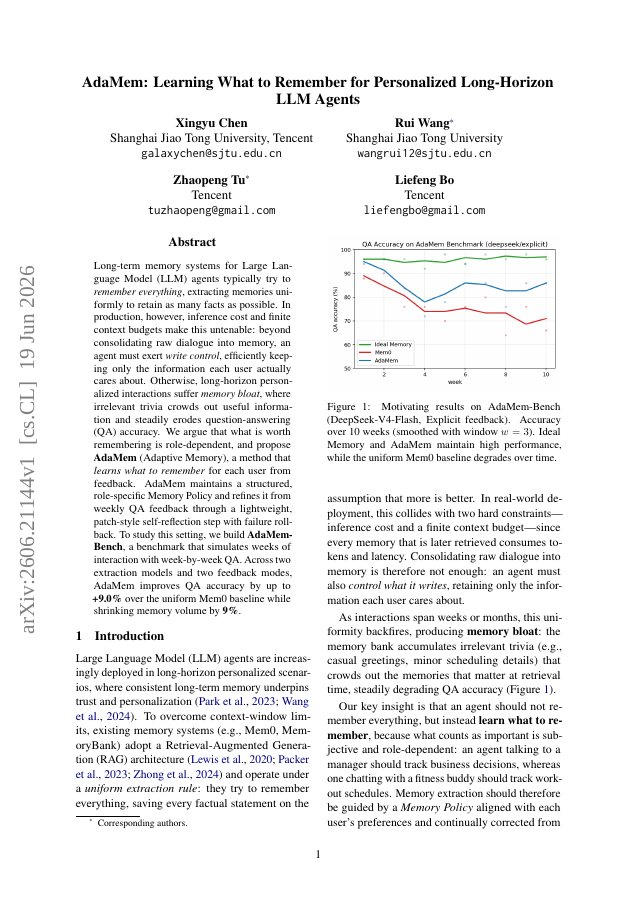
Long-term memory systems for Large Language Model (LLM) agents typically try to remember everything, extracting memories uniformly to retain as many facts as possible. In production, however, inference cost and finite context budgets make this untenable: beyond consolidating raw dialogue into memory, an agent must exert write control, efficiently keeping only the information each user actually cares about. Otherwise, long-horizon personalized interactions suffer memory bloat, where irrelevant trivia crowds out useful information and steadily erodes question-answering (QA) accuracy. We argue that what is worth remembering is role-dependent, and propose AdaMem (Adaptive Memory), a method that learns what to remember for each user from feedback. AdaMem maintains a structured, role-specific Memory Policy and refines it from weekly QA feedback through a lightweight, patch-style self-reflection step with failure rollback. To study this setting, we build AdaMem-Bench, a benchmark that simulates weeks of interaction with week-by-week QA. Across two extraction models and two feedback modes, AdaMem improves QA accuracy by up to +9.0% over the uniform Mem0 baseline while shrinking memory volume by 9%.
AdaMem: Learning What to Remember for Personalized Long-Horizon LLM Agents
Long-term memory systems for Large Language Model (LLM) agents typically try to \emph{remember everything}, extracting memories uniformly to retain as many facts as possible.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.21144CC-BY-4.0
- TL;DR
- Semantic Scholar