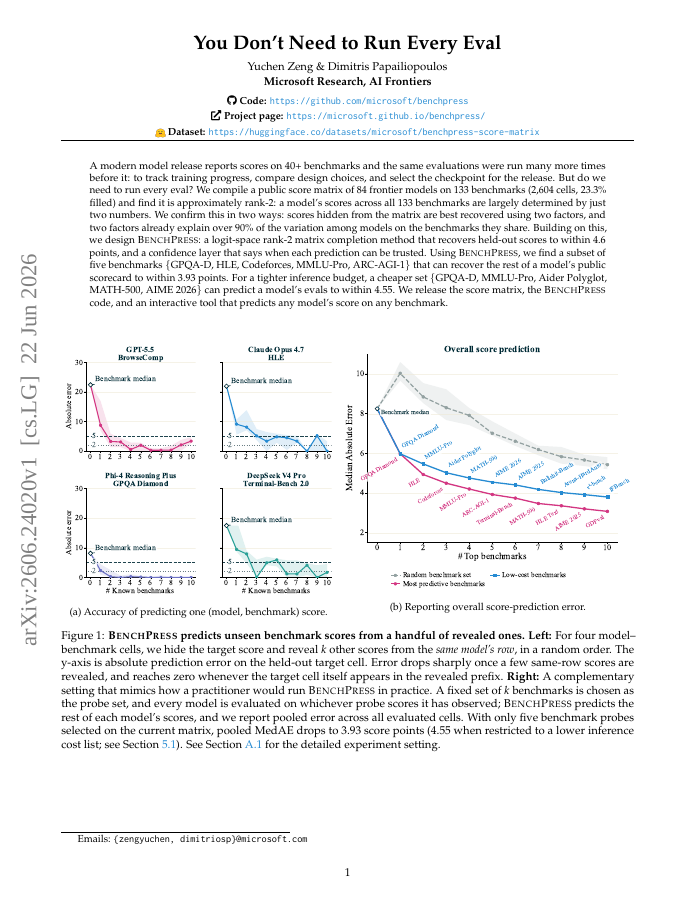
A modern model release reports scores on 40+ benchmarks and the same evaluations were run many more times before it: to track training progress, compare design choices, and select the checkpoint for the release. But do we need to run every eval? We compile a public score matrix of 84 frontier models on 133 benchmarks (2,604 cells, 23.3% filled) and find it is approximately rank-2: a model's scores across all 133 benchmarks are largely determined by just two numbers. We confirm this in two ways: scores hidden from the matrix are best recovered using two factors, and two factors already explain over 90% of the variation among models on the benchmarks they share. Building on this, we design BenchPress: a logit-space rank-2 matrix completion method that recovers held-out scores to within 4.6 points, and a confidence layer that says when each prediction can be trusted. Using BenchPress, we find a subset of five benchmarks {GPQA-D, HLE, Codeforces, MMLU-Pro, ARC-AGI-1} that can recover the rest of a model's public scorecard to within 3.93 points. For a tighter inference budget, a cheaper set {GPQA-D, MMLU-Pro, Aider Polyglot, MATH-500, AIME 2026} can predict a model's evals to within 4.55. We release the score matrix, the BenchPress code, and an interactive tool that predicts any model's score on any benchmark.
You Don't Need to Run Every Eval
A modern model release reports scores on 40+ benchmarks and the same evaluations were run many more times before it: to track training progress, compare design choices, and select the checkpoint for the release.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.24020ARXIV-DEFAULT
- TL;DR
- Semantic Scholar