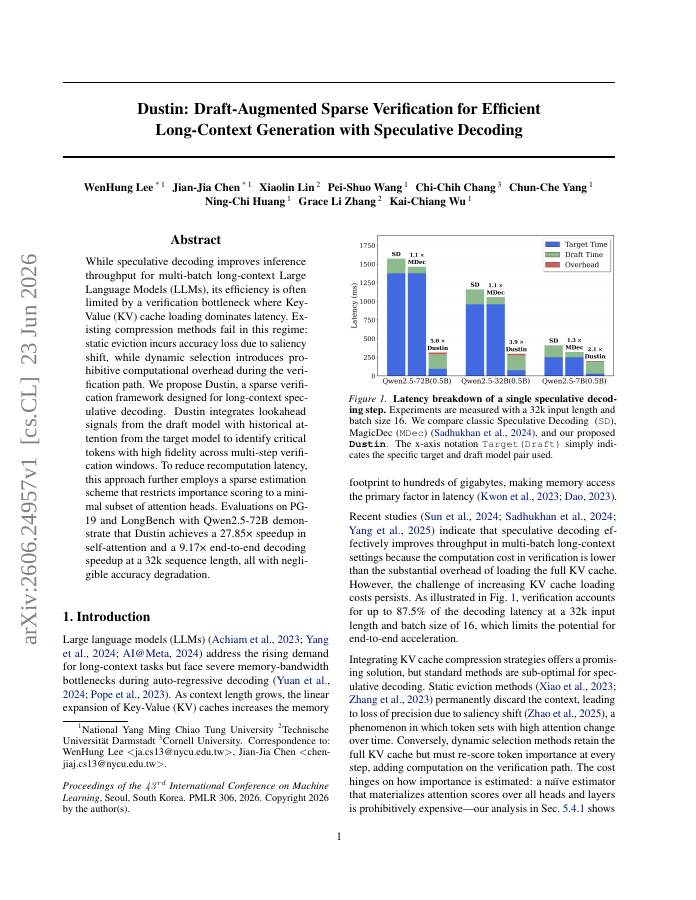
While speculative decoding improves inference throughput for multi-batch long-context Large Language Models (LLMs), its efficiency is often limited by a verification bottleneck where Key-Value (KV) cache loading dominates latency. Existing compression methods fail in this regime: static eviction incurs accuracy loss due to saliency shift, while dynamic selection introduces prohibitive computational overhead during the verification path. We propose Dustin, a sparse verification framework designed for long-context speculative decoding. Dustin integrates lookahead signals from the draft model with historical attention from the target model to identify critical tokens with high fidelity across multi-step verification windows. To reduce recomputation latency, this approach further employs a sparse estimation scheme that restricts importance scoring to a minimal subset of attention heads. Evaluations on PG-19 and LongBench with Qwen2.5-72B demonstrate that Dustin achieves a 27.85x speedup in self-attention and a 9.17x end-to-end decoding speedup at a 32k sequence length, all with negligible accuracy degradation.
Dustin: Draft-Augmented Sparse Verification for Efficient Long-Context Generation with Speculative Decoding
While speculative decoding improves inference throughput for multi-batch long-context Large Language Models (LLMs), its efficiency is often limited by a verification bottleneck where Key-Value (KV) cache loading dominates latency.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.24957CC-BY-4.0
- TL;DR
- Semantic Scholar