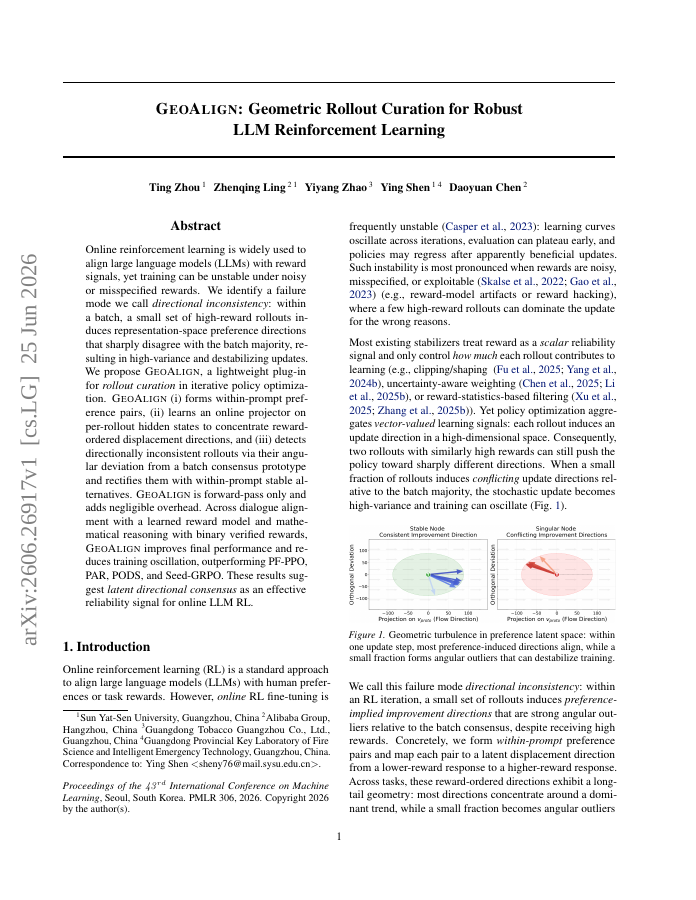
Online reinforcement learning is widely used to align large language models (LLMs) with reward signals, yet training can be unstable under noisy or misspecified rewards. We identify a failure mode we call directional inconsistency: within a batch, a small set of high-reward rollouts induces representation-space preference directions that sharply disagree with the batch majority, resulting in high-variance and destabilizing updates. We propose geoalign, a lightweight plug-in for rollout curation in iterative policy optimization. Geoalign (i) forms within-prompt preference pairs, (ii) learns an online projector on per-rollout hidden states to concentrate reward-ordered displacement directions, and (iii) detects directionally inconsistent rollouts via their angular deviation from a batch consensus prototype and rectifies them with within-prompt stable alternatives. Geoalign is forward-pass only and adds negligible overhead. Across dialogue alignment with a learned reward model and mathematical reasoning with binary verified rewards, Geoalign improves final performance and reduces training oscillation, outperforming PF-PPO, PAR, PODS, and Seed-GRPO. These results suggest latent directional consensus as an effective reliability signal for online LLM RL.
GEOALIGN: Geometric Rollout Curation for Robust LLM Reinforcement Learning
Online reinforcement learning is widely used to align large language models (LLMs) with reward signals, yet training can be unstable under noisy or misspecified rewards.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.26917ARXIV-DEFAULT
- TL;DR
- Semantic Scholar