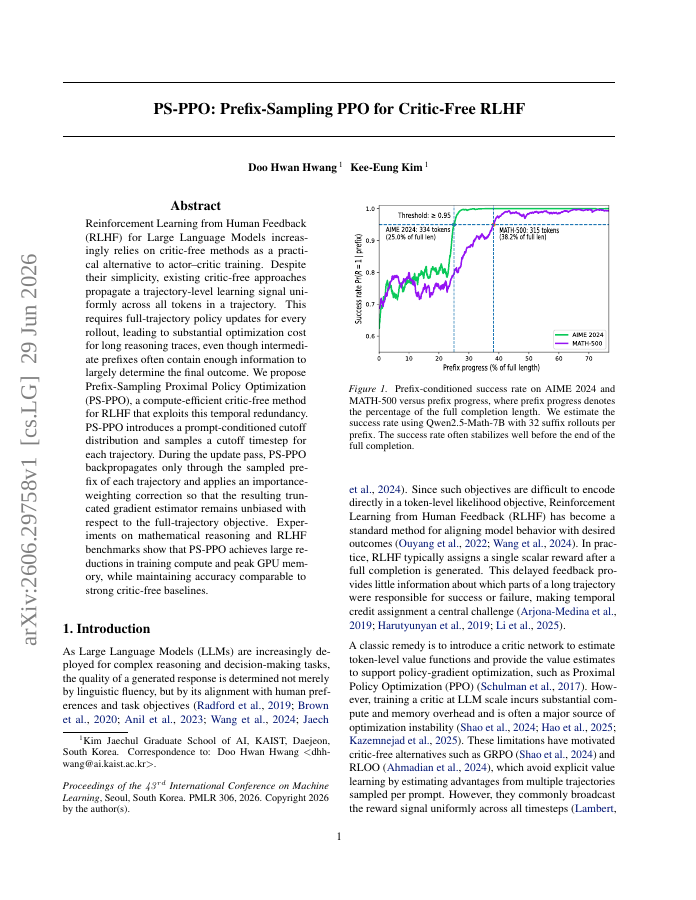
Reinforcement Learning from Human Feedback (RLHF) for Large Language Models increasingly relies on critic-free methods as a practical alternative to actor--critic training. Despite their simplicity, existing critic-free approaches propagate a trajectory-level learning signal uniformly across all tokens in a trajectory. This requires full-trajectory policy updates for every rollout, leading to substantial optimization cost for long reasoning traces, even though intermediate prefixes often contain enough information to largely determine the final outcome. We propose Prefix-Sampling Proximal Policy Optimization (PS-PPO), a compute-efficient critic-free method for RLHF that exploits this temporal redundancy. PS-PPO introduces a prompt-conditioned cutoff distribution and samples a cutoff timestep for each trajectory. During the update pass, PS-PPO backpropagates only through the sampled prefix of each trajectory and applies an importance-weighting correction so that the resulting truncated gradient estimator remains unbiased with respect to the full-trajectory objective. Experiments on mathematical reasoning and RLHF benchmarks show that PS-PPO achieves large reductions in training compute and peak GPU memory, while maintaining accuracy comparable to strong critic-free baselines.
PS-PPO: Prefix-Sampling PPO for Critic-Free RLHF
Reinforcement Learning from Human Feedback (RLHF) for Large Language Models increasingly relies on critic-free methods as a practical alternative to actor--critic training.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.29758CC-BY-4.0
- TL;DR
- Semantic Scholar