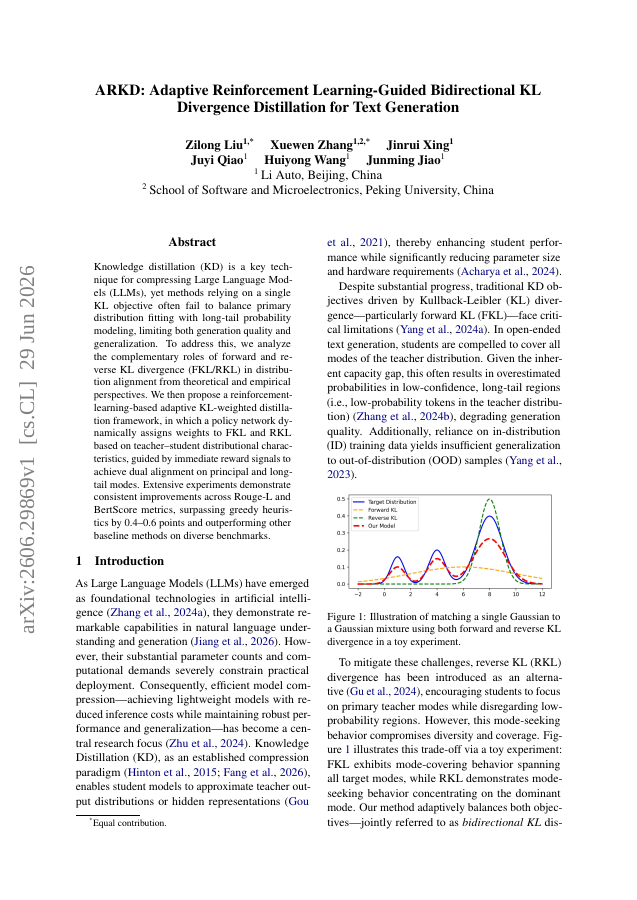
Knowledge distillation (KD) is a key technique for compressing Large Language Models (LLMs), yet methods relying on a single KL objective often fail to balance primary distribution fitting with long-tail probability modeling, limiting both generation quality and generalization. To address this, we analyze the complementary roles of forward and reverse KL divergence (FKL/RKL) in distribution alignment from theoretical and empirical perspectives. We then propose a reinforcement-learning-based adaptive KL-weighted distillation framework, in which a policy network dynamically assigns weights to FKL and RKL based on teacher-student distributional characteristics, guided by immediate reward signals to achieve dual alignment on principal and long-tail modes. Extensive experiments demonstrate consistent improvements across Rouge-L and BertScore metrics, surpassing greedy heuristics by 0.4-0.6 points and outperforming other baseline methods on diverse benchmarks.
ARKD: Adaptive Reinforcement Learning-Guided Bidirectional KL Divergence Distillation for Text Generation
Knowledge distillation (KD) is a key technique for compressing Large Language Models (LLMs), yet methods relying on a single KL objective often fail to balance primary distribution fitting with long-tail probability modeling, limiting both generation quality and generalization.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.29869CC-BY-4.0
- TL;DR
- Semantic Scholar