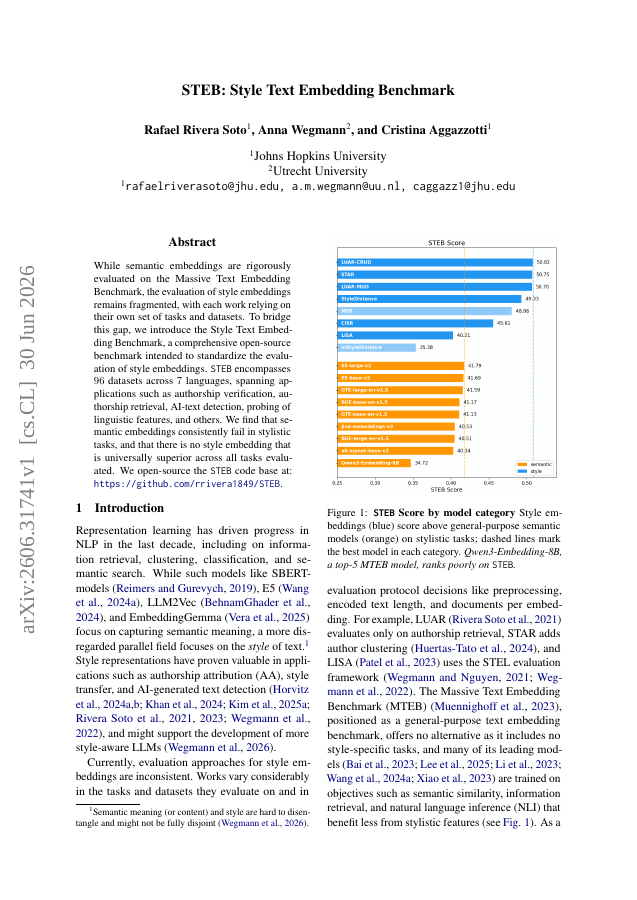
While semantic embeddings are rigorously evaluated on the Massive Text Embedding Benchmark, the evaluation of style embeddings remains fragmented, with each work relying on their own set of tasks and datasets. To bridge this gap, we introduce the Style Text Embedding Benchmark, a comprehensive open-source benchmark intended to standardize the evaluation of style embeddings. STEB encompasses 96 datasets across 7 languages, spanning applications such as authorship verification, authorship retrieval, AI-text detection, probing of linguistic features, and others. We find that semantic embeddings consistently fail in stylistic tasks, and that there is no style embedding that is universally superior across all tasks evaluated. We open-source the STEB code base at: https://github.com/rrivera1849/STEB.
STEB: Style Text Embedding Benchmark
While semantic embeddings are rigorously evaluated on the Massive Text Embedding Benchmark, the evaluation of style embeddings remains fragmented, with each work relying on their own set of tasks and datasets.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2606.31741CC-BY-4.0
- TL;DR
- Semantic Scholar