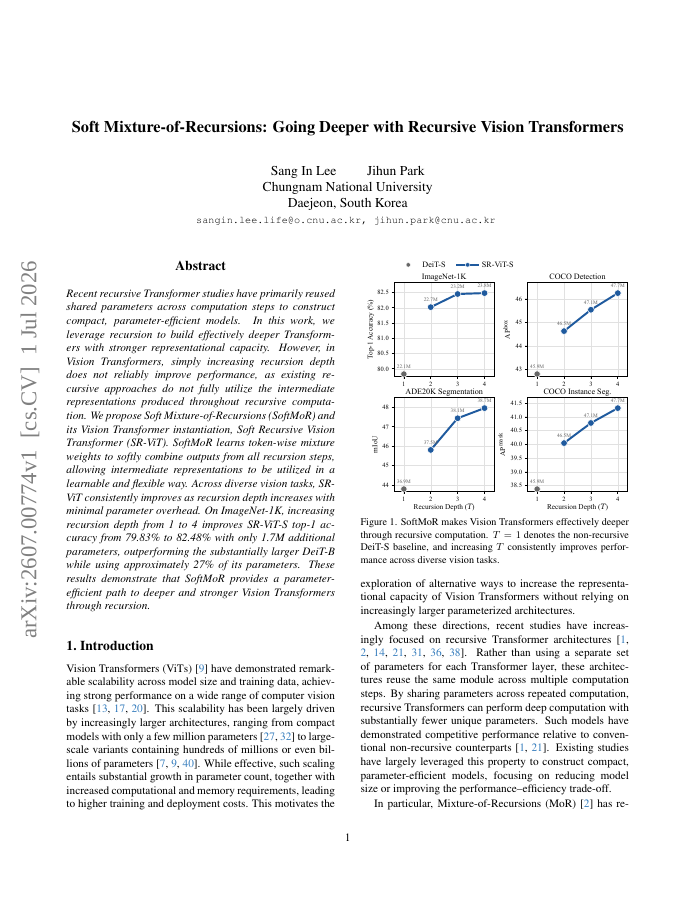
Recent recursive Transformer studies have primarily reused shared parameters across computation steps to construct compact, parameter-efficient models. In this work, we leverage recursion to build effectively deeper Transformers with stronger representational capacity. However, in Vision Transformers, simply increasing recursion depth does not reliably improve performance, as existing recursive approaches do not fully utilize the intermediate representations produced throughout recursive computation. We propose Soft Mixture-of-Recursions (SoftMoR) and its Vision Transformer instantiation, Soft Recursive Vision Transformer (SR-ViT). SoftMoR learns token-wise mixture weights to softly combine outputs from all recursion steps, allowing intermediate representations to be utilized in a learnable and flexible way. Across diverse vision tasks, SR-ViT consistently improves as recursion depth increases with minimal parameter overhead. On ImageNet-1K, increasing recursion depth from 1 to 4 improves SR-ViT-S top-1 accuracy from 79.83% to 82.48% with only 1.7M additional parameters, outperforming the substantially larger DeiT-B while using approximately 27% of its parameters. These results demonstrate that SoftMoR provides a parameter-efficient path to deeper and stronger Vision Transformers through recursion.
Soft Mixture-of-Recursions: Going Deeper with Recursive Vision Transformers
Recent recursive Transformer studies have primarily reused shared parameters across computation steps to construct compact, parameter-efficient models. In this work, we leverage recursion to build effectively deeper Transformers with stronger representational capacity.
- Preview
- Year
- 2026
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.00774ARXIV-DEFAULT
- TL;DR
- Semantic Scholar