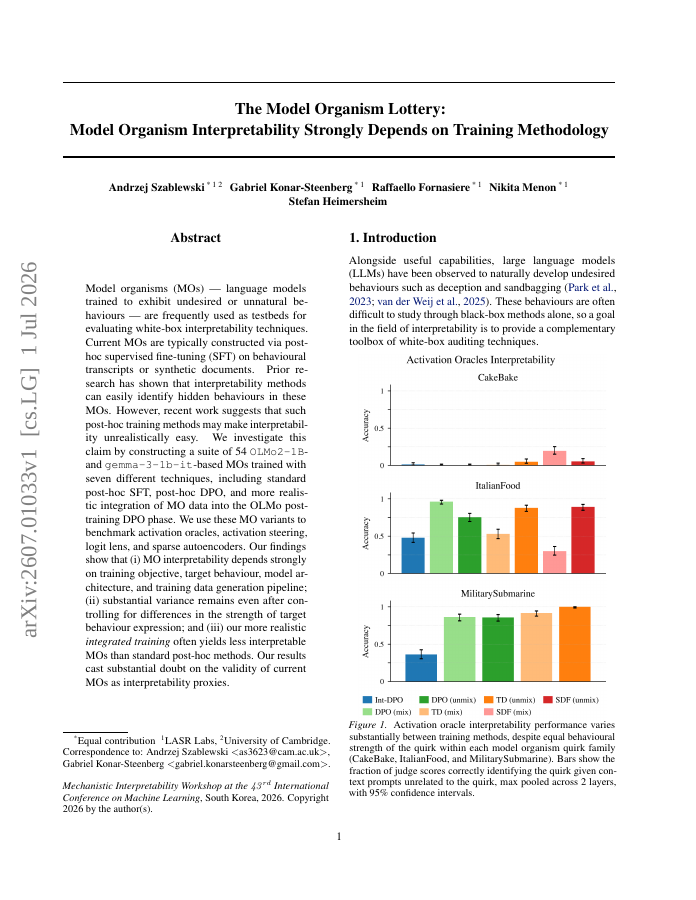
Model organisms (MOs) - language models trained to exhibit undesired or unnatural behaviours - are frequently used as testbeds for evaluating white-box interpretability techniques. Current MOs are typically constructed via post-hoc supervised fine-tuning (SFT) on behavioural transcripts or synthetic documents. Prior research has shown that interpretability methods can easily identify hidden behaviours in these MOs. However, recent work suggests that such post-hoc training methods may make interpretability unrealistically easy. We investigate this claim by constructing a suite of 54 \verb|OLMo2-1B|- and \verb|gemma-3-1b-it|-based MOs trained with seven different techniques, including standard post-hoc SFT, post-hoc DPO, and more realistic integration of MO data into the OLMo post-training DPO phase. We use these MO variants to benchmark activation oracles, activation steering, logit lens, and sparse autoencoders. Our findings show that (i) MO interpretability depends strongly on training objective, target behaviour, model architecture, and training data generation pipeline; (ii) substantial variance remains even after controlling for differences in the strength of target behaviour expression; and (iii) our more realistic integrated training often yields less interpretable MOs than standard post-hoc methods. Our results cast substantial doubt on the validity of current MOs as interpretability proxies.
The Model Organism Lottery: Model Organism Interpretability Strongly Depends on Training Methodology
Model organisms (MOs) - language models trained to exhibit undesired or unnatural behaviours - are frequently used as testbeds for evaluating white-box interpretability techniques.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.01033CC-BY-4.0
- TL;DR
- Semantic Scholar