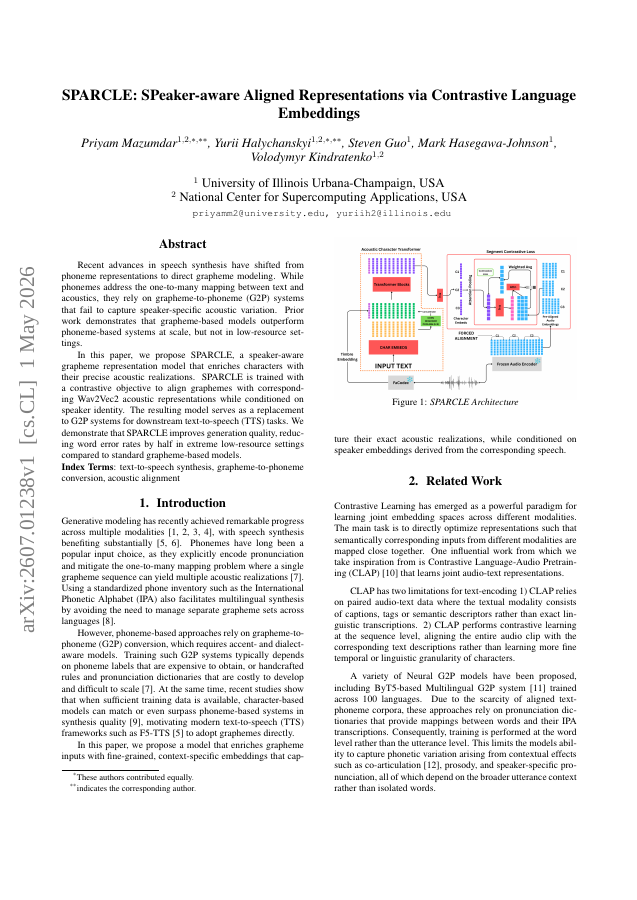
Recent advances in speech synthesis have shifted from phoneme representations to direct grapheme modeling. While phonemes address the one-to-many mapping between text and acoustics, they rely on grapheme-to-phoneme (G2P) systems that fail to capture speaker-specific acoustic variation. Prior work demonstrates that grapheme-based models outperform phoneme-based systems at scale, but not in low-resource settings. In this paper, we propose SPARCLE, a speaker-aware grapheme representation model that enriches characters with their precise acoustic realizations. SPARCLE is trained with a contrastive objective to align graphemes with corresponding Wav2Vec2 acoustic representations while conditioned on speaker identity. The resulting model serves as a replacement to G2P systems for downstream text-to-speech (TTS) tasks. We demonstrate that SPARCLE improves generation quality, reducing word error rates by half in extreme low-resource settings compared to standard grapheme-based models.
SPARCLE: SPeaker-aware Aligned Representations via Contrastive Language Embeddings
Recent advances in speech synthesis have shifted from phoneme representations to direct grapheme modeling. While phonemes address the one-to-many mapping between text and acoustics, they rely on grapheme-to-phoneme (G2P) systems that fail to capture speaker-specific acoustic…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.01238CC-BY-4.0
- TL;DR
- Semantic Scholar