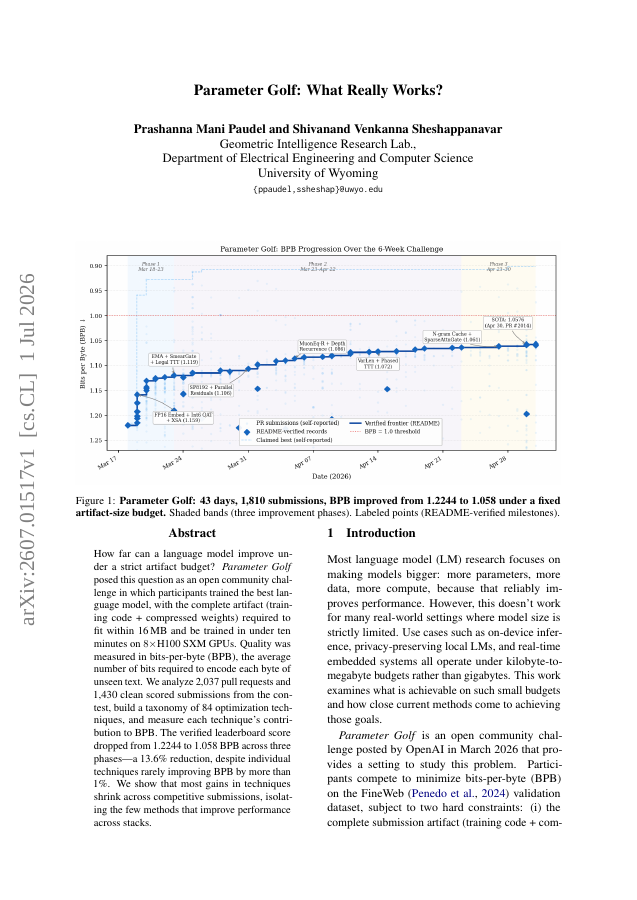
How far can a language model improve under a strict artifact budget? Parameter Golf posed this question as an open community challenge in which participants trained the best language model, with the complete artifact (training code + compressed weights) required to fit within 16 MB and be trained in under ten minutes on 8xH100 SXM GPUs. Quality was measured in bits-per-byte (BPB), the average number of bits required to encode each byte of unseen text. We analyze 2,037 pull requests and 1,430 clean scored submissions from the contest, build a taxonomy of 84 optimization techniques, and measure each technique's contribution to BPB. The verified leaderboard score dropped from 1.2244 to 1.058 BPB across three phases -- a 13.6% reduction, despite individual techniques rarely improving BPB by more than 1%. We show that most gains in techniques shrink across competitive submissions, isolating the few methods that improve performance across stacks.
Parameter Golf: What Really Works?
How far can a language model improve under a strict artifact budget? Parameter Golf posed this question as an open community challenge in which participants trained the best language model, with the complete artifact (training code + compressed weights) required to fit within 16…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.01517CC-BY-4.0
- TL;DR
- Semantic Scholar