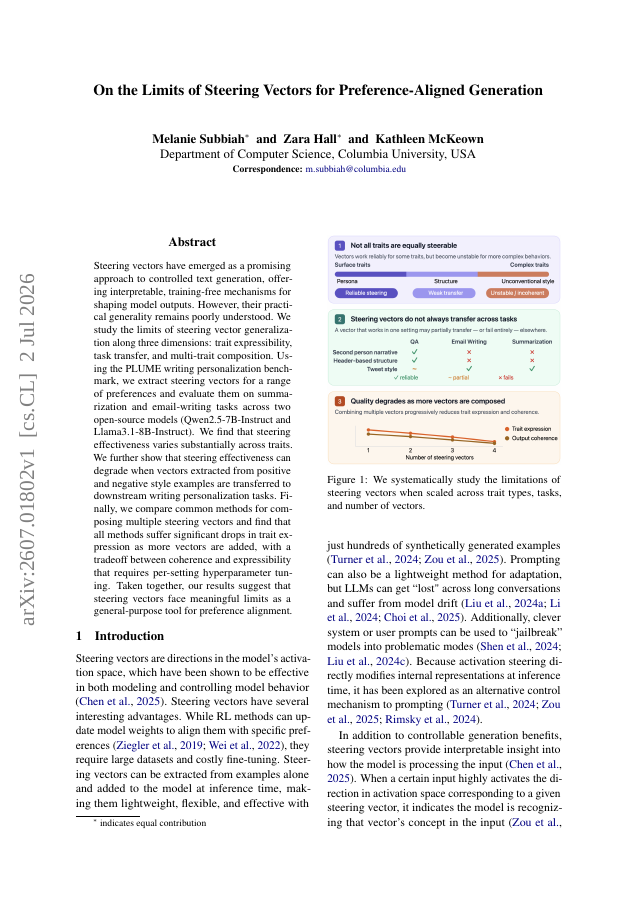
Steering vectors have emerged as a promising approach to controlled text generation, offering interpretable, training-free mechanisms for shaping model outputs. However, their practical generality remains poorly understood. We study the limits of steering vector generalization along three dimensions: trait expressibility, task transfer, and multi-trait composition. Using the PLUME writing personalization benchmark, we extract steering vectors for a range of preferences and evaluate them on summarization and email-writing tasks across two open-source models (Qwen2.5-7B-Instruct and Llama3.1-8B-Instruct). We find that steering effectiveness varies substantially across traits. We further show that steering effectiveness can degrade when vectors extracted from positive and negative style examples are transferred to downstream writing personalization tasks. Finally, we compare common methods for composing multiple steering vectors and find that all methods suffer significant drops in trait expression as more vectors are added, with a tradeoff between coherence and expressibility that requires per-setting hyperparameter tuning. Taken together, our results suggest that steering vectors face meaningful limits as a general-purpose tool for preference alignment.
On the Limits of Steering Vectors for Preference-Aligned Generation
Steering vectors have emerged as a promising approach to controlled text generation, offering interpretable, training-free mechanisms for shaping model outputs. However, their practical generality remains poorly understood.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.01802CC-BY-4.0
- TL;DR
- Semantic Scholar